Date created: Wednesday, June 22, 2016 9:23:41 AM. Last modified: Thursday, April 28, 2022 2:45:05 PM
ASR9000 Series Hardware Overview
References:
https://community.cisco.com/t5/service-providers-documents/ios-xr-release-strategy-and-deployment-recommendation/ta-p/3165422
http://www.cisco.com/c/en/us/products/collateral/routers/asr-9000-series-aggregation-services-routers/data_sheet_c78-663866.html
http://www.cisco.com/c/en/us/products/collateral/routers/asr-9000-series-aggregation-services-routers/datasheet-c78-733763.html
https://www.ciscoknowledgenetwork.com/files/515_04-07-15-ASR_HD9k_CKN_v5_Final.pdf?PRIORITY_CODE=
http://www.cisco.com/c/en/us/td/docs/routers/asr9000/hardware/overview/guide/asr9kOVRGbk/asr9kOVRGfuncdescription.html
https://supportforums.cisco.com/document/105496/asr9000xr-understanding-route-scale
https://supportforums.cisco.com/document/12153086/asr9000xr-understanding-fabric-and-troubleshooting-commands
https://supportforums.cisco.com/document/93456/asr9000xr-local-packet-transport-services-lpts-copp
RKSPG-2904 - ASR-9000/IOS-XR hardware Architecture, QOS, EVC, IOS-XR Configuration and Troubleshooting
https://supportforums.cisco.com/document/91676/asr9000xr-what-difference-between-p-and-px-files
Introduction to IOS-XR 6.0
BRKARC-2017 - Packet Journey inside ASR 9000
https://www.cisco.com/c/en/us/products/collateral/routers/asr-9000-series-aggregation-services-routers/datasheet-c78-741101.html
https://www.cisco.com/c/en/us/products/collateral/routers/asr-9000-series-aggregation-services-routers/datasheet-c78-741127.html
https://www.cisco.com/c/en/us/products/collateral/routers/asr-9000-series-aggregation-services-routers/datasheet-c78-741128.html
Cisco ASR 9000 Series (codename "Viking") Hardware Overview.
Contents:
Chassis Types
RSP/RP/NPUs
Switch Fabric
Fabric Interconnects
Ethernet Line Cards
Packet Forwarding
Virtual Output Queues and The Arbiter
NP Architecture
IOS-XR Software Versions
LPTS - Local Packet Transport Services
- ASR 9001 codename "Iron Man"
- Supports 40Gbps per MPA slot (2 slots total).
- Uses RSP2 (some sort of Typhoon-RP2 hybrid?).
- Internally uses an integrated fabric with MOD80SE and x2 Typhoon NPUs (MOD-80 is codenamed "WeaponX-2").
- ASR 9901 codename "Starlord"
- Fixed chassis with no MPAs and 2x100G QSFP28, 24x10G/1G SFP+ and 16x1G SFP ports.
- Internally uses 2x Tomahawk NPUs with shared TCAM and integrated fabric.
- ASR 9006
- Supports up to 1.8Tbps per slot non-resiliently or up to 880Gbps per slot resiliently.
- Uses RSP440, RSP880, A9K-RSP5 and A9K-RSP.
- Supports MOD80 SE/TR, MOD160 SE/TR, MOD200 SE/TR, MOD400 SE/TR (MOD-160 is codenamed "WeaponX-4").
- Fabric is on the RP - no fabric cards.
- ASR 9010
- Supports upto 1.8Tbps per slot non-resiliently or up to 880Gbps per slot resiliently.
- Uses RSP-4G, RSP440, RSP880, A9K-RSP5 and A9K-RSP.
- Supports MOD80 SE/TR, MOD160 SE/TR, MOD200 SE/TR, MOD400 SE/TR.
- Fabric is on the RP - no fabric cards.
- ASR 9904 codename "Tardis"
- Supports up to 3.6bps per slot non-resiliently or 1.8Tbps resiliently.
- Uses RSP440, RSP880 and A9K-RSP5
- Supports MOD200 SE/TR, MOD400 SE/TR.
- Higher end cards like A9K-2x100GE-TR or A9K-36x10GE-TR are full width and don't use MODs.
- Fabric is on the RP - no fabric cards.
- ASR 9906
- Uses A99-RSP and A9K-RSP5.
- Supports up to 4.2Tbps per slot non-resiliently or up to 3.6Gbps per slot resiliently.
- Fabric is mixed, integrated in RP and uses fabric cards.
- ASR 9910
- Uses A99-RSP and A9K-RSP5.
- Supports up to 4.2Tbps per slot non-resiliently or up to 3.6Gbps per slot resiliently.
- Supports MOD200 SE/TR, MOD400 SE/TR.
- Higher end cards like A9K-2x100GE-TR or A9K-36x10GE-TR are full width and don't use MODs.
- Fabric is mixed, integrated in RP and uses fabric cards.
- ASR 9912 codename "Starscream"
- Supports 2Tbps per slot.
- Uses ASR-9900-RP and A99-RP2/RP3.
- Supports MOD200 SE/TR, MOD400 SE/TR.
- Higher end cards like A9K-2x100GE-TR or A9K-36x10GE-TR are full width and don't use MODs.
- Fabric is fully distributed on fabric cards.
- ASR 9922 codename "Megatron"
- Supports 4Tbps per slot.
- Uses ASR-9900-RP, ASR-9922-RP and A99-RP2/RP3.
- Supports MOD200 SE/TR, MOD400 SE/TR.
- Higher end cards like A9K-2x100GE-TR or A9K-36x10GE-TR are full width and don't use MODs.
- Fabric is fully distributed on fabric cards.
- 1st Gen: Trident line cards are 32 bit Freescale PPC LC CPUs.
- Trident cards come as service-edge-optimised (SE) or packet-transport-optimised (TR).
- Examples of Trident cards include the 40x1GE card (A9K-40GE "Ryan"), the 4x10GE card (A9K-4T), the 8x10GE card (A9K-8T "Odin") and 16x10GE card (A9K-16 "Valhalla").
- The Ezchip Trident NPU is a 90nm 15Gbps (~15Mpps) rated Full Duplex NPU that feeds a 60Gbps Fabric Interconnect ASIC (Octopus) which feeds a Santa Cruz 90Gbps Fabric Switching ASIC.
- Trident cards support 512K IPv4 / 128K IPv6 shared prefix space, this is shared RLDRAM memory (Trident cards use sub-trees so it is possible that certain VRFs run out of space before others, default scale profile is 128k prefixes per sub-tree/VRF).
- Trident cards have a fixed 256K MPLS label TCAM space.
- Will scale to 1.3M IPv4 / 650K IPv6 shared prefix space and 256K prefixes per sub-tree.
- Trident cards are based off of the 7600 series ES+ line cards, they use the same SANTA_CRUZ ASIC and Ezchip NP3C NPU (more details here also see here [CSCuz35344] that NP3C support is discontinued in IOS-XR 6.0.1 and thus Trident cards are no longer supported).
- 2nd Gen: Typhoon line cards are 32 bit Freescale PPC CPUs (P4040 4 cores @ 1.5Ghz)
- Typhoon cards come as service-edge-optimised (SE) or packet-transport-optimised (TR).
- Examples of Typhoon cards include the 2x10G+16x1G card (A9K-4T16GE-SE "Wildchild").
- The Ezchip Typhoon NPU is a 55nm 60Gbps (~45Mpps) rated Full Duplex NPU that feeds a 60Gbps Skytrain Fabric Interconnect ASIC which feeds a 220Gbps Sacramento Fabric Switching ASIC.
- Typhon cards support 4M IPv4 or 2M IPv6 prefixes (Typhoon cards use MTRIE so there are no scaling issues like with the Trident cards which use sub-trees).
- Typhoon cards support 1M MPLS labels.
- The search memory (1M labels, 2M MAC, 4M/2M v4/v6 routes) in the NPU is RLDRAM and there are separate L2 and L3 search memories so no scale profiles as with Trident which uses a shared search memory for L2 and L3.
- The Typhoon NPU has 2GB of packet buffers (~100ms) and 256k egress queues per NPU.
- 3rd Gen: Tomhawk line cards use 6-core Intel x86 64 bit CPUs (Ivy Bridge EN 6 cores @ 2Ghz)
- Tomahawk cards come as service-edge-optimised (SE) or packet-transport-optimised (TR).
- Examples of Tomahawk cards include the 16x100GE card (A9K-16X100GE "Azteca").
- Tomahawk line cards use the Ezchip Tomahawk NPU which is a 28nm chip which runs up to 240Gbps Full Duplex (150Mpps) feeding into a 200Gbps Tigershark Fabric Interconnect ASIC, feeding into a 1.20Tbps SM15 Fabric Switching ASIC.
- The 200Gbps FIA means that certain Ethernet line cards like the 24x10G (1xTomahawk NPU) and 48x10G (2xTomahawk NPU) are slightly oversubscribed.
- Tomahawk cards support 4M IPv4 or 2M IPv6 prefixes (Tomahawk cards use MTRIE so there are no scaling issues like with the Trident cards which use sub-trees).
- Tomahawk cards support 1M MPLS labels.
- The search memory (1M labels, 2M MAC, 4M/2M v4/v6 routes) in the NPU is RLDRAM and there are separate L2 and L3 search memories so no scale profiles as with Trident which uses a shared search memory for L2 and L3.
- Each Tomahawk NPU has 12GB of packet buffers (~200ms) and 1M egress queues per NPU.
- 4th Gen: Lightspeed line cards use a 8-core x86 64 bit CPU
- Lightspeed cards come as service-edge-optimised (SE) or packet-transport-optimised (TR).
- Examples of the Lightspeed cards include the 16x100GE 32x100GE QSFP cards (A9K-16X100GE-SE/TR and A99-32X100GE-SE/TR).
- Lightspeed cards use the Cisco internal NPU which is a 16nm chip which runs up to 400Gbps Full Duplex feeding the 3.59Tbps Skybolt Fabric Switching ASIC. This is a collapsed NPU/card architecture with the FIA is integrated into the NPU. This means the card topology is NPU <> Fabric ASIC and not NPU <> FIA <> Fabric ASIC.
- The fabric arbiter and VoQ controlling ASIC is called Tornado.
- The ASR9000-RP2 uses a dual-core 32 bit Freescale PPC CPU (8641D @ 1.5Ghz)
- 4GBs of SD RAM expandable to 8GB.
- The two fabric chips on the RSP2 are Santa Cruz chips, it has a single Octopus Fabric Interface Chip and a single Arbiter chip which is Bellagio.
- 184Gbps supported per slot with dual RSP2s.
- The ASR9001 RSP uses a 32 bit quad-core Freescale PPC CPU (P4040 @ 1.5Ghz)
- The ASR9001s use a fixed Typhoon based forwarding platform so they support 4M IPv4 or 2M IPv6 prefixes (shared TCAM) and 1M MPLS labels.
- The ASR9001s use a fixed Typhoon based forwarding platform so they support 4M IPv4 or 2M IPv6 prefixes (shared TCAM) and 1M MPLS labels.
- The RSP440 uses a quad-core Intel x86 64 bit CPU (Jasper Forest @ 2.27Ghz)
- The two fabric chips on the RSP440 are Santa Cruz chips, it has a single Octopus Fabric Interface Chip and a single Arbiter chip which is Bellagio.
- An RSP440 is either service-edge-optimised (SE) or packet-transport-optimised (TR) and both models support both SE and TR and line cards (which can be mixed together in the same chassis).
- The two variants come with 8GBs or 16GBs of DDR3 RAM.
- A single RSP440 provides 220Gbps of full duplex switch fabric capacity per line card slot.
- Dual RSP440s provides 220Gbps of full duplex switch fabric capacity per line card slot in redundant 1+1 mode and 440Gbps switch fabric capacity per slot in non-redundant (dual active RSP) mode.
- The RSP440-Lite is a 160Gbps license restricted version of the RSP440 which can be license upgrade to full capacity.
- RSP880 uses an x86 64 bit Intel CPU (8 cores @ 1.9Ghz Ivy Bridge EP)
- "Tomahawk" (3rd) generation fabric and RSP.
- An RSP880 is either service-edge-optimised (SE) or packet-transport-optimised (TR) and both models support both SE and TR and line cards (which can be mixed together in the same chassis).
- Both SE and TR variants are available as an optional RL (rate-limited) version limited down to 440Gbps (A9K-RSP880-RL-SE and A9K-RSP880-RL-TR) which are license upgradable to 880Gbps.
- The two variants come with (TR) 16GBs or (SE) 32GBs of DRAM
- A single RSP880 provides 440Gbps of full duplex switch fabric capacity per line card slot.
- Dual RSP880s provide 440Gbps of full duplex switch fabric capacity per line card slot in redundant 1+1 mode, or 880Gbps of switch fabric capacity per line card slot in non-redundant (dual active RSP) mode.
- Tomahawk LCs like the 4x100G and 8x100G can be used with Typhoon line cards with an RSP440 although only half the forwarding capacity is available with an RSP440 (they are not compatible with any Trident line cards). The 2x100G is codenamed "Juggernaut".
- RSP880-LT uses an x86 64 bit Intel CPIU (4 cores @ 2.4GHz Broadwell)
- The RSP880-LT is [new] variant that provides 880Gbps of resilient fabric capacity.
- It comes in the same TR/SE 16GB/32GB variants.
- Support in 9006/9010/9910/9906/9904 chassis.
- The RP1 uses a quad-core Intel x86 64 bit CPU (2.27Ghz)
- 6GB TR version, 12GB SE version.
- 6GB TR version, 12GB SE version.
- The RP2 uses an x86 64 bit Intel CPU (8 cores @ 1.9Ghz Ivy Bridge EP)
- 16GB TR version, 32GB SE version.
- 16GB TR version, 32GB SE version.
- A9K-RSP-4G/8G
- A9K-RSP-4G and A9K-RSP-8G are the 4G and 8G RAM variants respectively.
- A9K-RSP5-SE/TR uses an x86 64 bit Intel CPU (8 cores @ 1.9Ghz Skylake EP)
- "Lightspeed" (4th) generation fabric and RSP.
- 16GB TR versions are retired, now 24GB TR version, 32GB SE version.
- With 16GBs of memory Cisco officially support up to 2M IPv4 routes in RIB, 10M IPv4 routes iwith 24GBs.
- Acts as the fabric in the 9010, 9006, 9904 and 9906 chassis.
- Acts as a fabrc card inside a 9912 and 9922 chassis which can control upto 5 other fabric cards.
- ASR-9900-RP-SE/TR
- Used in ASR9912 and ASR9922 only.
- 6GB TR and 12GB SE versions.
- ASR-9922-RP-SE/TR
- Used in ASR9922 only.
- 6GB TR and 12GB SE versions.
- A99-RSP-SE/TR uses an x86 64 bit Intel CPU (8 cores @ 1.9Ghz Ivy Bridge EP)
- "Tomahawk" (3rd) generation fabric and RSP.
- 16GB TR version, 32GB SE version.
- A99-RP2-SE/TR uses an x86 64bit Intel CPU (8 cores @ 1.9Ghz Ivy Bridge EP)
- "Tomahawk" (3rd) generation fabric and RSP.
- 16GB TR version, 32GB SE version.
- A99-RP3-SE/TR uses an x86 64 bit Intel CPU (8 cores @ 2Ghz Skylake EP)
- "Lightspeed" (4th) generation fabric RSP.
- 16GB TR version, 40GB SE version.
- Uses eXR which runs a Sysadmin VM called "Calvados".
OOB ports on RPs/RSPs can only forward OOB traffic only. Line card interfaces can forward transit traffic and in-band management traffic. In the case that an OOB port is in the same routing table as a line card port, traffic cannot route between the two even if the correct routing information is present.
ASR9000 series routers have a fully distributed switch fabric to interconnect all the line card slots in the chassis. In ASR9006, ASR9010, ASR9904 and ASR9910 chassis all line cards connect to the switch fabric on the RSP. In the ASR9912 and ASR9922 chassis all line cards connect to the switch fabric on the Fabric Controller (FC) cards.
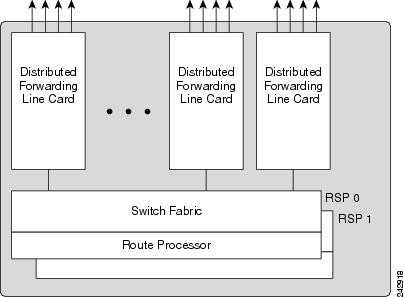
ASR9006, ASR9010, ASR9904 and ASR9910 Switch Fabric on the RSPs:
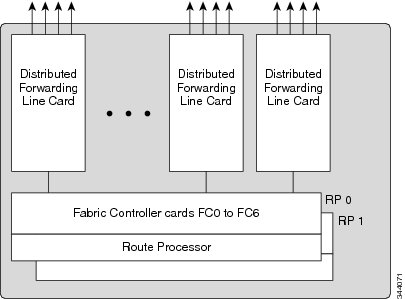
ASR9912 and ASR9922 Switch Fabric cards:
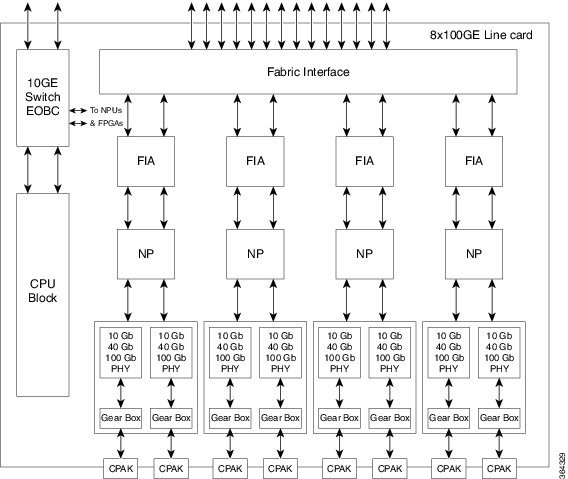
ASR9000 8x100GE Line Card:
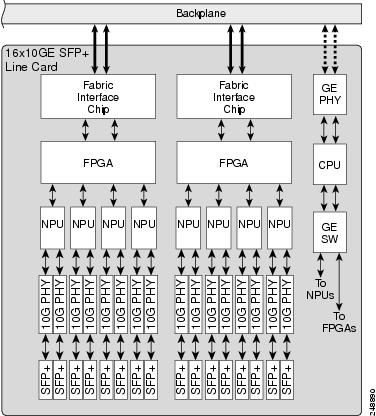
ASR9000 16x 10GE SFP Line Card:
ASR9922 and ASR9912 Backplane:
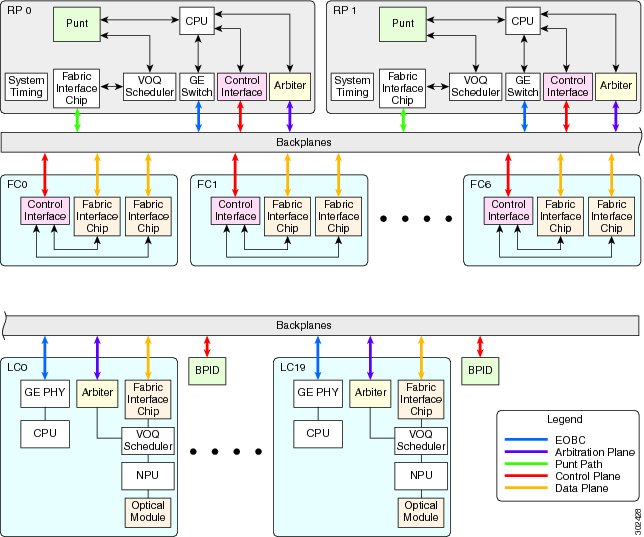
The RSP card in an ASR9006, ASR9010, ASR9904 and ASR9910 provides system control, packet switching, and timing control for the system. The RSP contains the switch fabric, dual RSPs provide resiliency. For ASR9912 and ASR9922 chassis using the RP, the switch fabric has been moved onto dedicated Fabric Controller cards. The RS still provides system control, packet switching, and timing control for the system. Like an RSP, dual RP cards provides resiliency. Both the RSP/RP cards provide shared resources for backplane Ethernet communication, system timing (frequency and time of date) synchronization, precision clock synchronization, chassis control, power control (through a separate CAN bus controller network) and boot media.
An RSP/RP communicates with other route processors and linecards over a switched Ethernet out-of-band channel (EOBC) for management and control purposes.
RSP Component Interconnects:
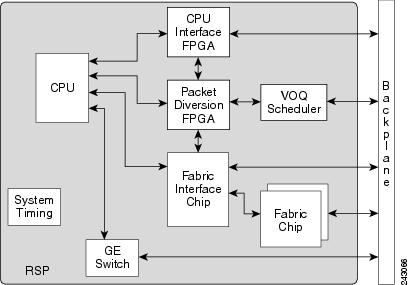
RP Components Interconnects:
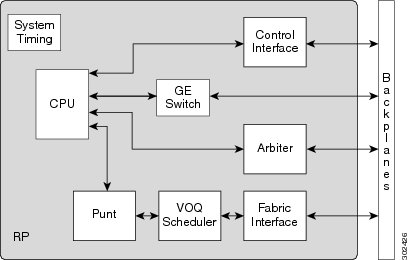
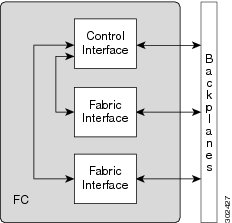
Fabric Controller Component Interconnects:
The RSP/RP EOBC Gigabit Ethernet switch is for processor-to-processor communication, such as IPC (InterProcess Communication). The Active RSP/RP card also uses the EOBC to communicate to the Standby RSP/RP card, if installed (the RSP-880 and RSP2 cards have10GE switches used for EOBC).
ASR 9000 Line Card EOBC Interconnects: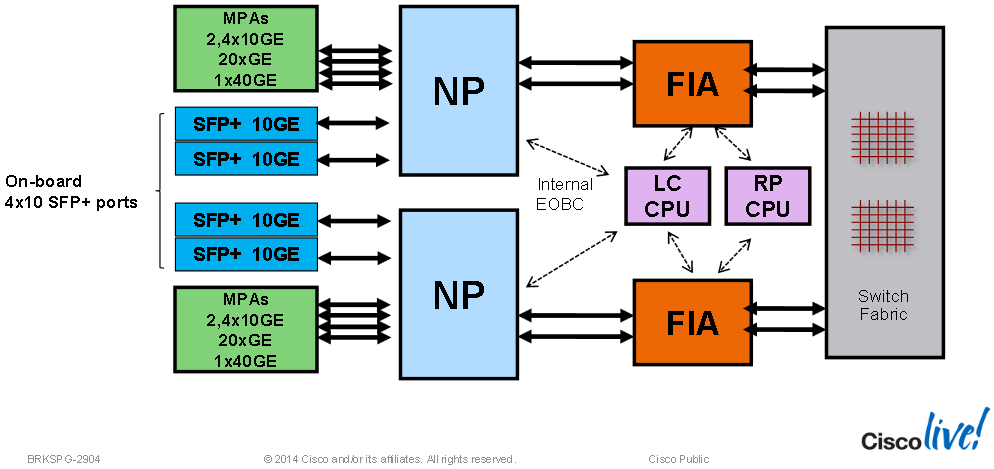
The switch fabric is configured as a single stage of switching with multiple parallel planes. The fabric is responsible for getting packets from one line card to another, but has no packet processing capabilities. Each fabric plane is a single-stage, non-blocking, packet-based, store-and-forward switch. To manage fabric congestion, the RSP card also provides centralized Virtual Output Queue (VOQ) arbitration.
The switch fabric is 1+1 redundant, with one copy of the fabric on each redundant RSP card. Each RSP card carries enough switching capacity to meet the router throughput specifications, allowing for full redundancy.
- In systems with the RSP card, the switch fabric delivers up to 80-Gbps per line card slot.
- In systems with the RSP-440 card or RSP-440 Lite card, the switch fabric delivers up to 220-Gbps per line card slot in redundant 1+1 mode and up to 440-Gbps per line card slot in non-redundant mode (two active RSPs).
- In systems with the RSP4-S card the switch fabric delivers up to 220-Gbps per line card slot in redundant 1+1 mode and up to 440-Gbps per line card slot in non-redundant mode (two active RSPs).
- In systems with the RSP-880 card, the switch fabric delivers up to 440-Gbps per line card slot in redundant 1+1 mode and up to 880-Gbps per line card slot in non-redundant mode (two active RSPs).
In the Cisco ASR 9922 Router and Cisco ASR 9912 Router, the switch fabric resides on dedicated line cards that connect to the backplanes alongside the RP cards.
- For first and second generation line cards, the Cisco ASR 9922 Router and Cisco ASR 9912 Router support up to five FCs in the chassis. Each FC card delivers 110G per slot. For example, when five FCs are installed in the chassis, the switch fabric is considered 4+1 redundant (one card in standby mode and four cards active), thereby delivering 440Gbps per line card slot. In non-redundant mode, the switch fabric delivers 550-Gbps per line card slot.
- For third generation line cards, the Cisco ASR 9922 Router and Cisco ASR 9912 Router support up to seven FCs in the chassis. Each FC card carries 230G per slot. For example, when five FCs are installed in the chassis, the switch fabric is 4+1 redundant (one card in standby mode and four cards active), thereby delivering 920-Gbps per slot (230x4). In non-redundant mode, the switch fabric delivers 1.15 Tbps per line card.
- When all seven FC cards are installed in the chassis, the switch fabric is 6+1 redundant one card in standby mode and six cards in active), and is capable of delivering up to 1.38 Tbps per slot (230x6).
Triden Switch Fabric Interconnects: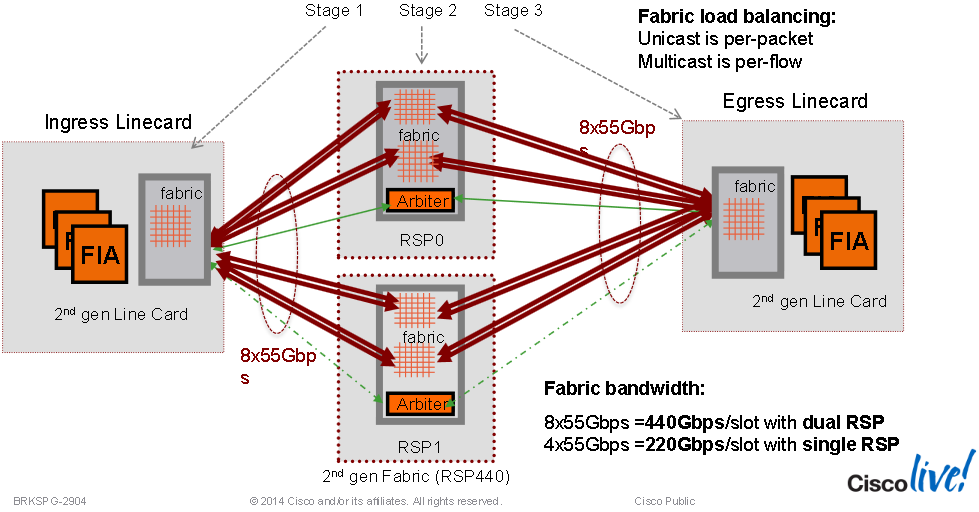
Typhoon Switch Fabric Interconnects: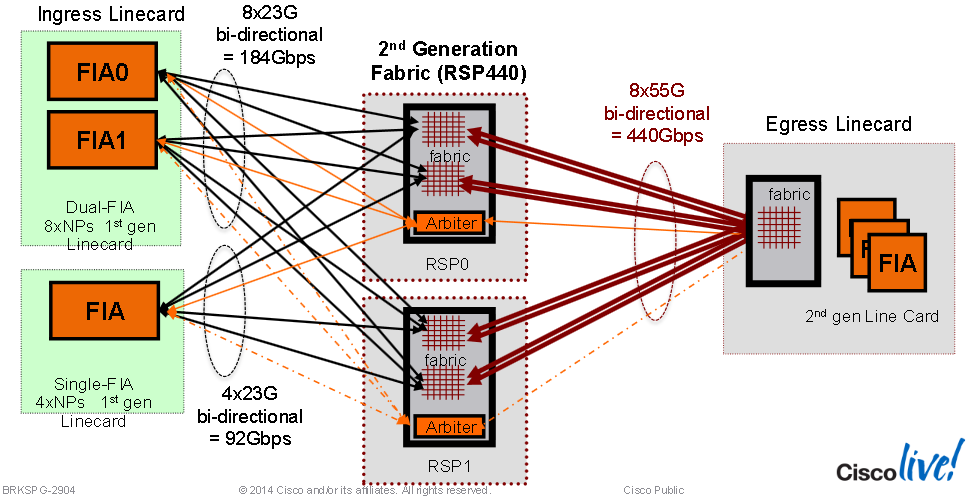
ASR9006 and ASR9010 Switch Fabric Interconnects:
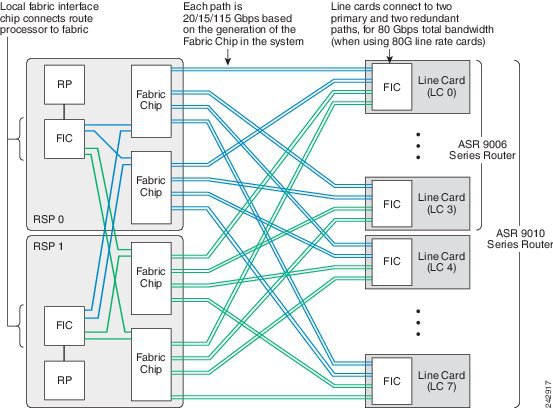
ASR9904 Switch Fabric Interconnects:
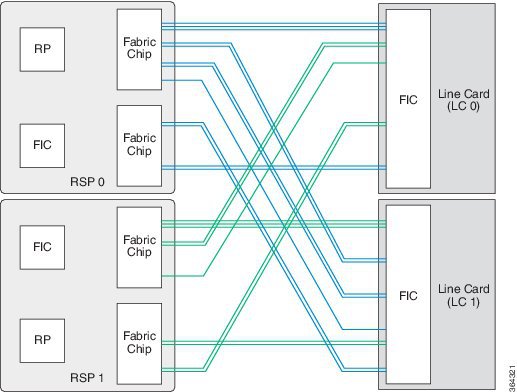
ASR9922 Switch Fabric Interconnnects (the ASR9912 is the same with support for only 10 line cards and a single Fabric Interconnect Chip):
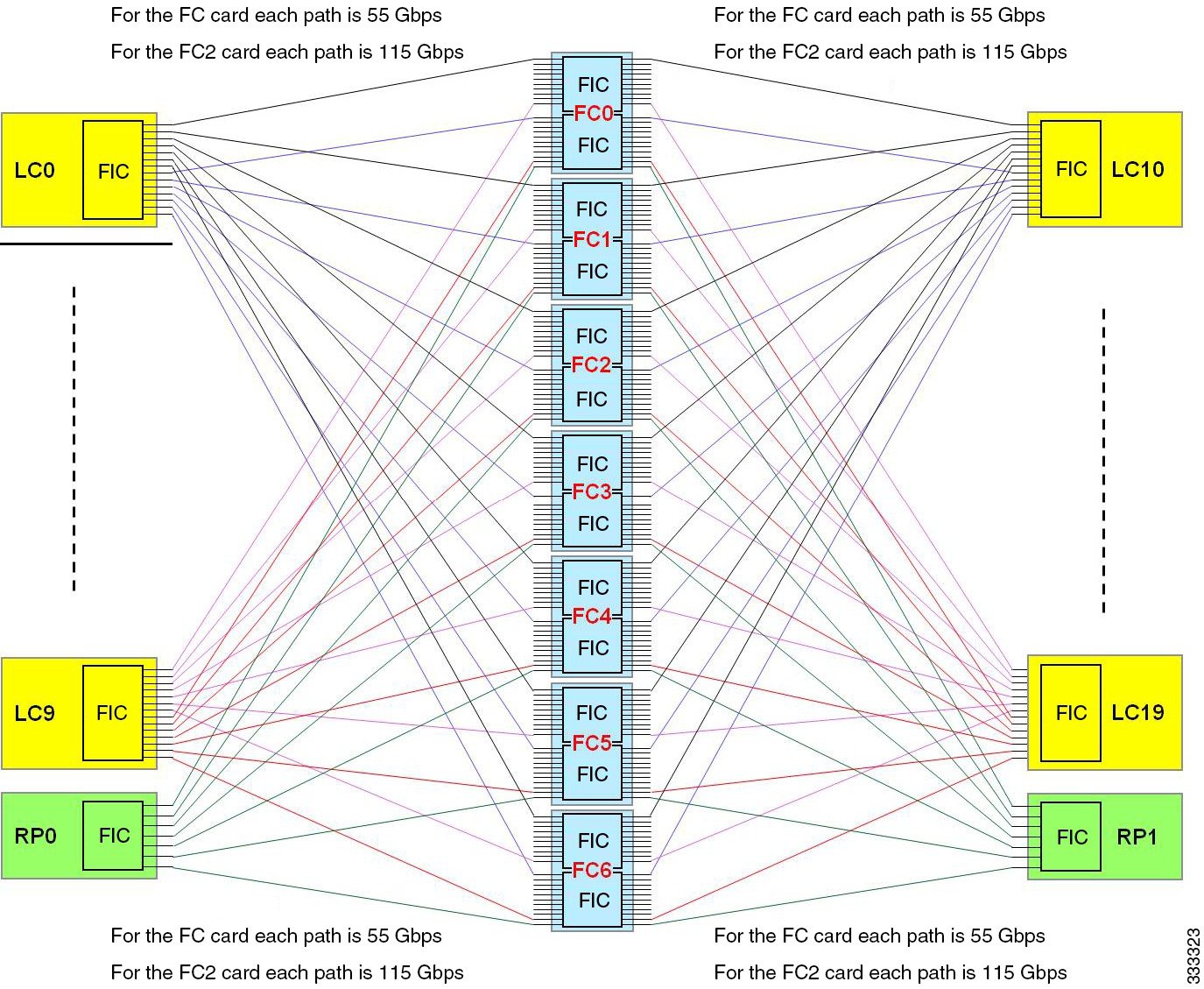
ASR9912/ASR9922 Typhoon Line Card Overview: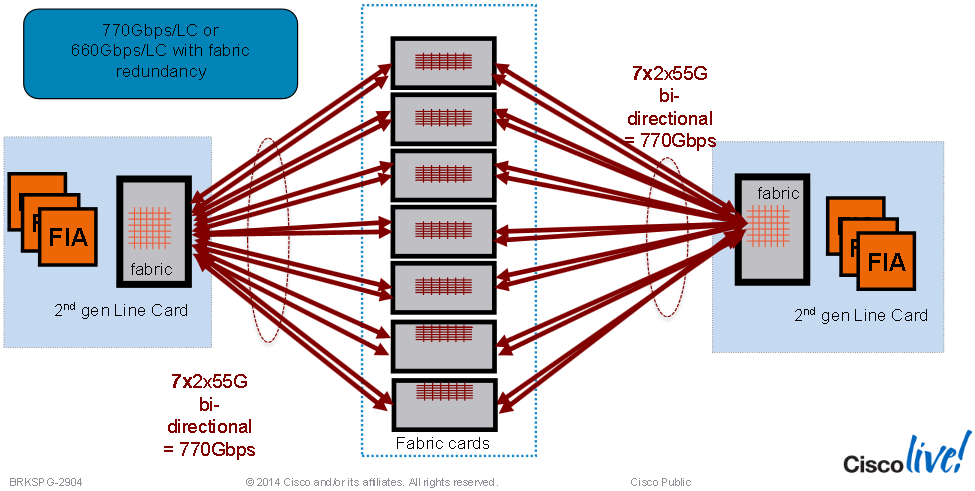
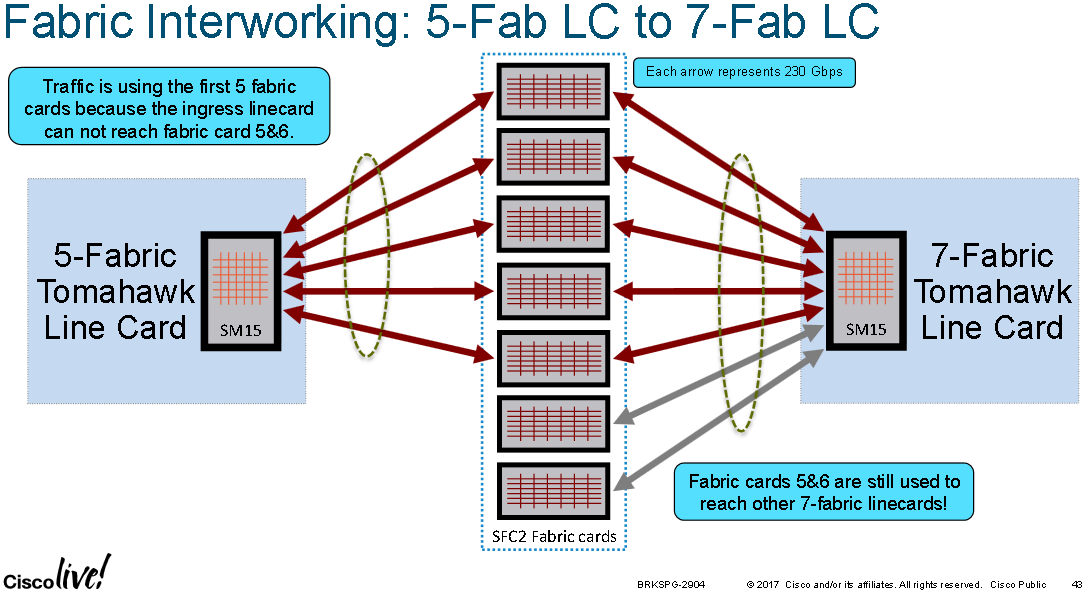
When mixing 5 fabric plane cards with 7 fabric plane cards, the 7 fabric plane cards don't downgrade to 5 lanes, they will use 7 lanes to talk to other 7 lane cards, but only 5 lanes to 5 lane cards:
The RSP card has a fabric interface chip (FIC) attached to the switch fabric and linked to the Route Processor through a Gigabit Ethernet interface through a packet diversion FPGA. This path is used for external traffic diverted to the RSP card by line card network processors.
The packet diversion FPGA has three key functions:
- Packet header translation between the header used by the fabric interface chip and the header exchanged with the Ethernet interface on the route processor.
- I/O interface protocol conversion (rate-matching) between the 20-Gbps DDR bus from the fabric interface chip and the 1-Gbps interface on the processor.
- Flow control to prevent overflow in the from-fabric buffer within the packet diversion FPGA, in case of fabric congestion.
The Route Processor communicates with the switch fabric via a FIC to process control traffic. The FIC has sufficient bandwidth to handle the control traffic and flow control in the event of fabric congestion. External traffic is diverted to the Route Processor by the line card network processors.
The RP and FC cards in the Cisco ASR 9922 Router have control interface chips and FICs attached to the backplanes that provide control plane and punt paths.
Just as a FIC sits is on the RP/RSP and connects it to switch fabric, the Fabric Interconnect ASIC (FIA) sits on a line card and connects it to the switch fabric (RSPs may have more than one FIC and Ethernet line cards may have more than one FIA, typically one FIA per NPU).
The FIA provides the data connection to switch fabric, manages VoQs, superframing, loadbalancing data traffic across the switch fabric lanes and the multicast replication table for replication toward NPs.
Ethernet line cards for the Cisco ASR 9000 Series Routers provide forwarding throughput of line rate for packets as small as 64 bytes. The small form factor pluggable (SFP, SFP+, QSFP+, XFP, CFP, or CPAK) transceiver module ports are polled periodically to keep track of state changes and optical monitor values. Packet features are implemented within network processor unit (NPU) ASICs
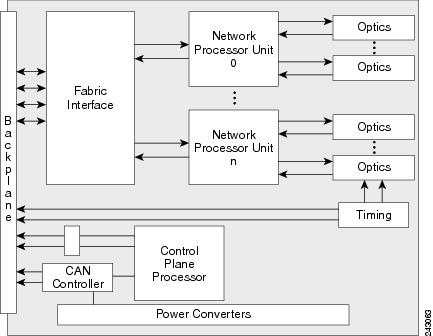
The optics, NPU and fabric interface handles all main data and also controls data that are routed to the RSP/RP cards. The other path is to the local CPU through a switched Gigabit Ethernet link. This second link is used to process control data routed to the line card CPU or packets sent to the RSP/RP card through the fabric link. The backplane Gigabit Ethernet links, one to each RSP/RP card, are used primarily for control plane functions such as application image download, system configuration data from the IOS XR software, statistics gathering, and line card power-up and reset control.
The number of NPUs will vary depending on the number of ports. Each NPU can handle millions of packets per second, accounting for ingress and egress, with a simple configuration. The more packet processing features enabled, the lower the packets per second that can be processed in the pipeline. There is a minimum packet size of 64 bytes, and a maximum packet size of 9 KB (9216 bytes) from the external interface.
36x 10G Typhoon Card Overview: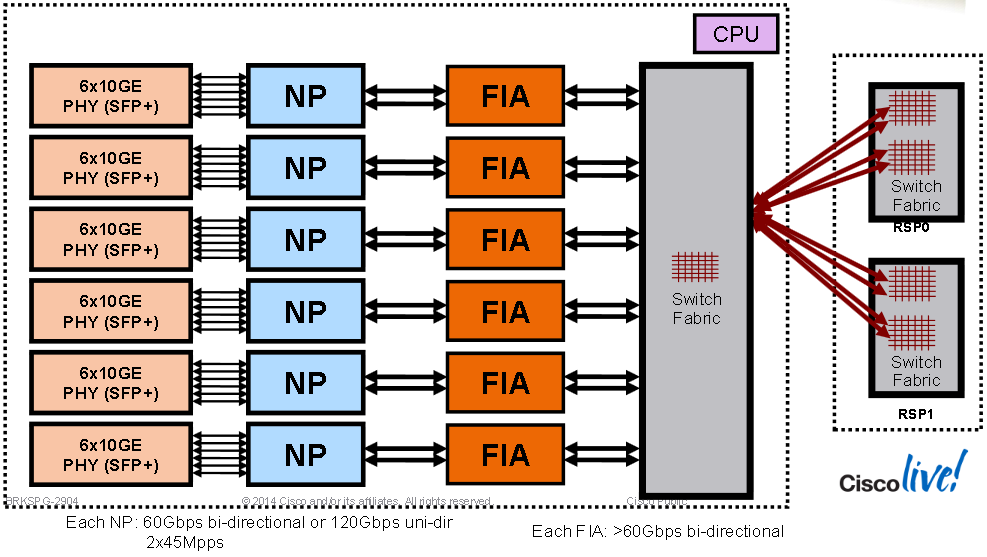
2x 100G Tomahawk Line Card Overview: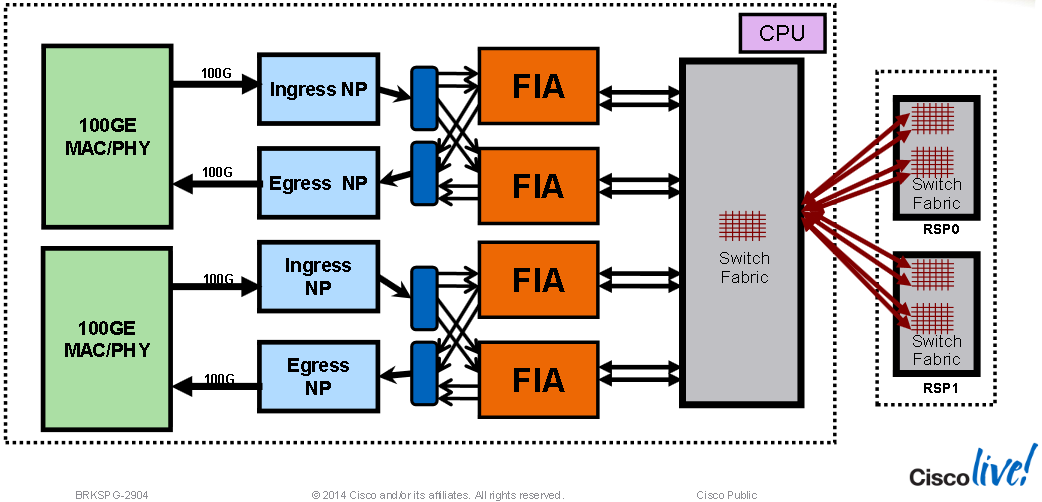
8x100G (A9K-8X100G-TR/SE) Line Card:
The A99-12X100GE "Skyhammer" line card and A99-8X100GE "Octane" line card require the ASR9900 series 7-fabic plane achitecture to attain line rate. The ASR9000 5-fabric plane architecture only supports the 48x10, MOD200/400, A9K-4X100GE-* ("Mini Skyhammer"), A9K-8X100G-* cards at line rate.
12x 100G Tomahawk Line Card Overview:
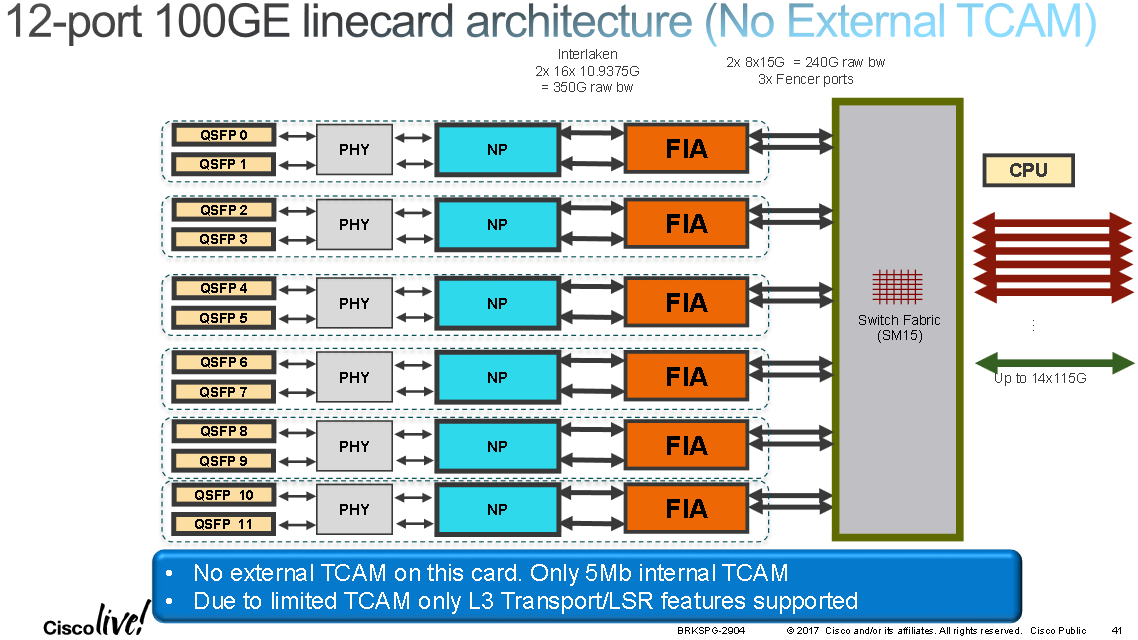
IOS-XR has evolved from being 32bit QNX based to 64bit Linux based. Care must be taken when pairing certain line cards with certain XR versions. The A9K-48X10GE-1G-SE/TR and A9K-24X10GE-1G-SE/TR linecards (codenamed "Powerglide") are dual rate 10G/1G line cards which are not supported on eXR (the Linux based variant of IOS-XR).
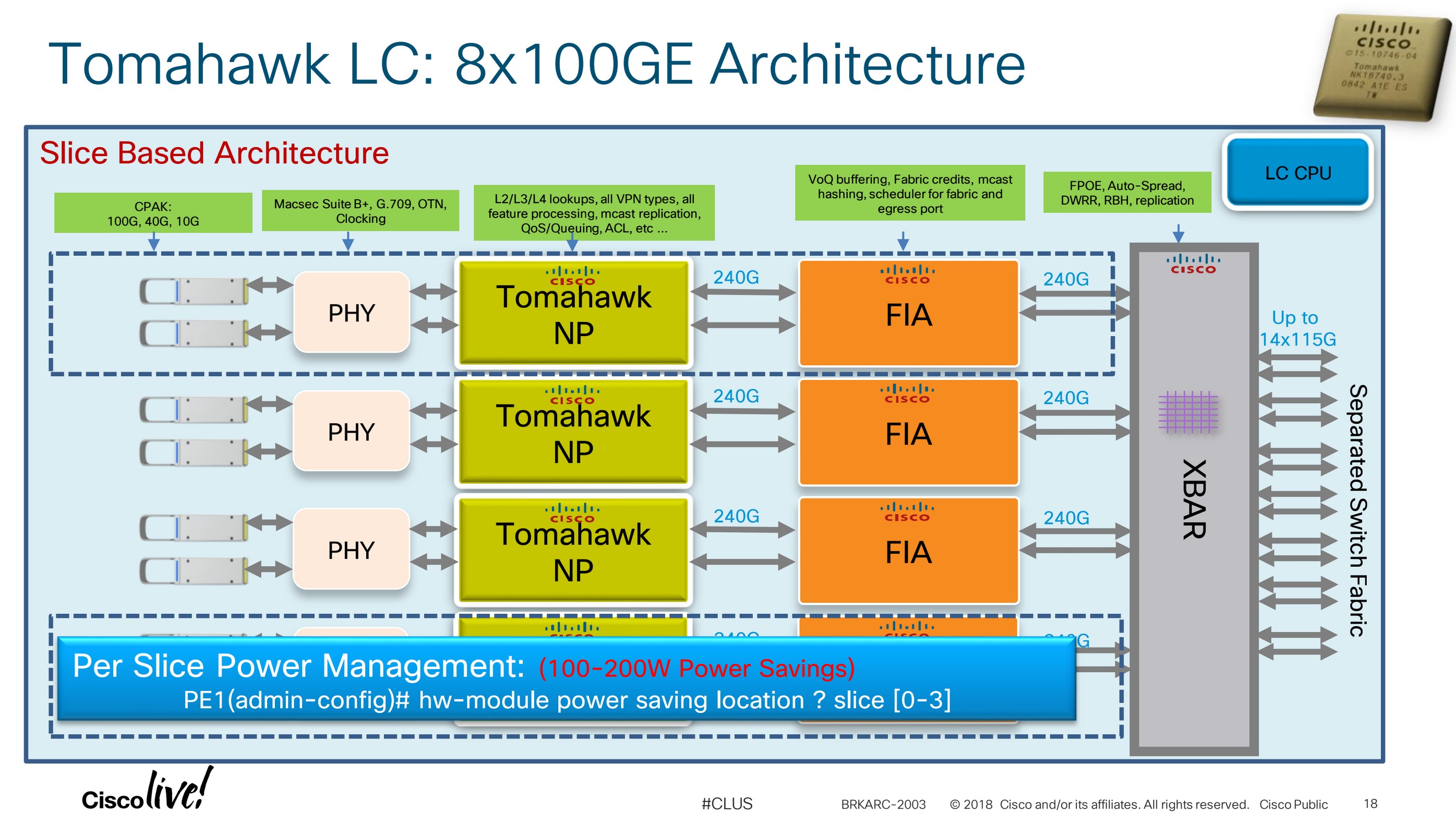
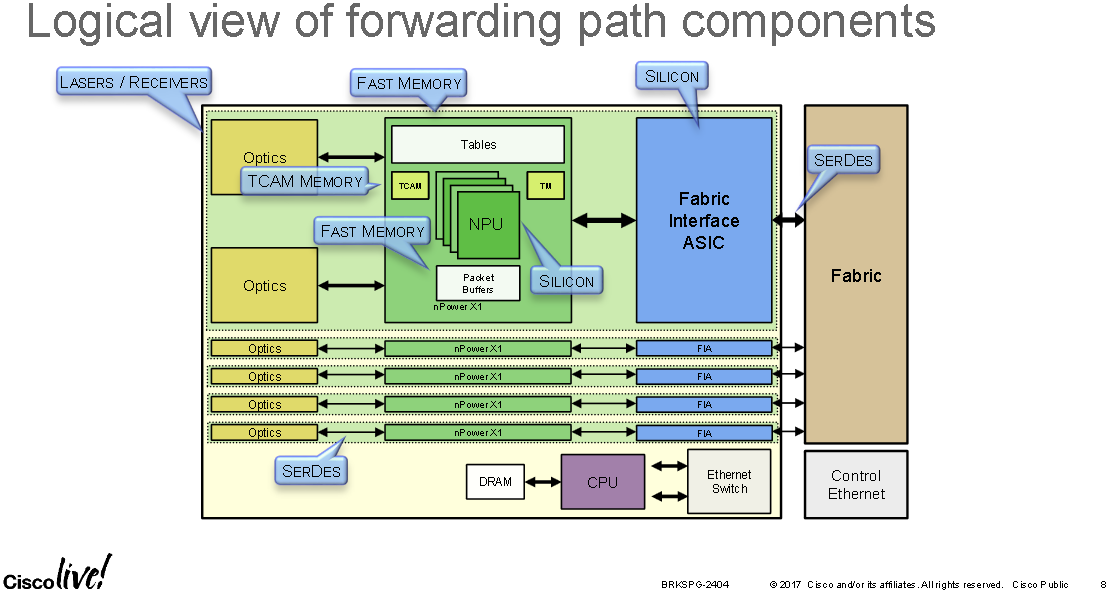
The following diagram is of a Cisco NCS 6000 line card but the same applies to the ASR9000 series line cards; it shows that newer cards are made us using "slices". One slice has been annotated with two optic ports, an NPU and FIA; when both of the ports on this slice are disconnected/unused the slice within this line card can shutdown vai the CLI to save power, without effecting the performance of the rest of the card or chassis:
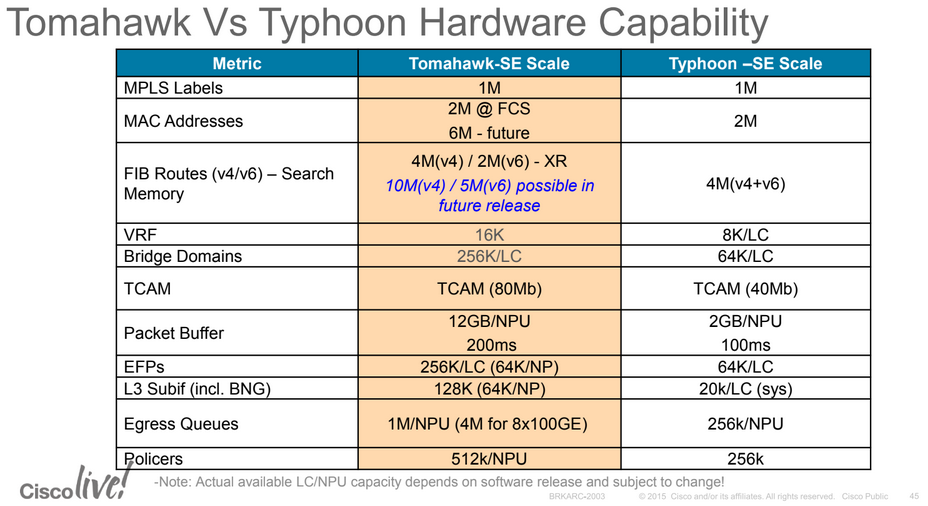
The following slide shows some Typhon and Tomahawk NPU scaling limits:
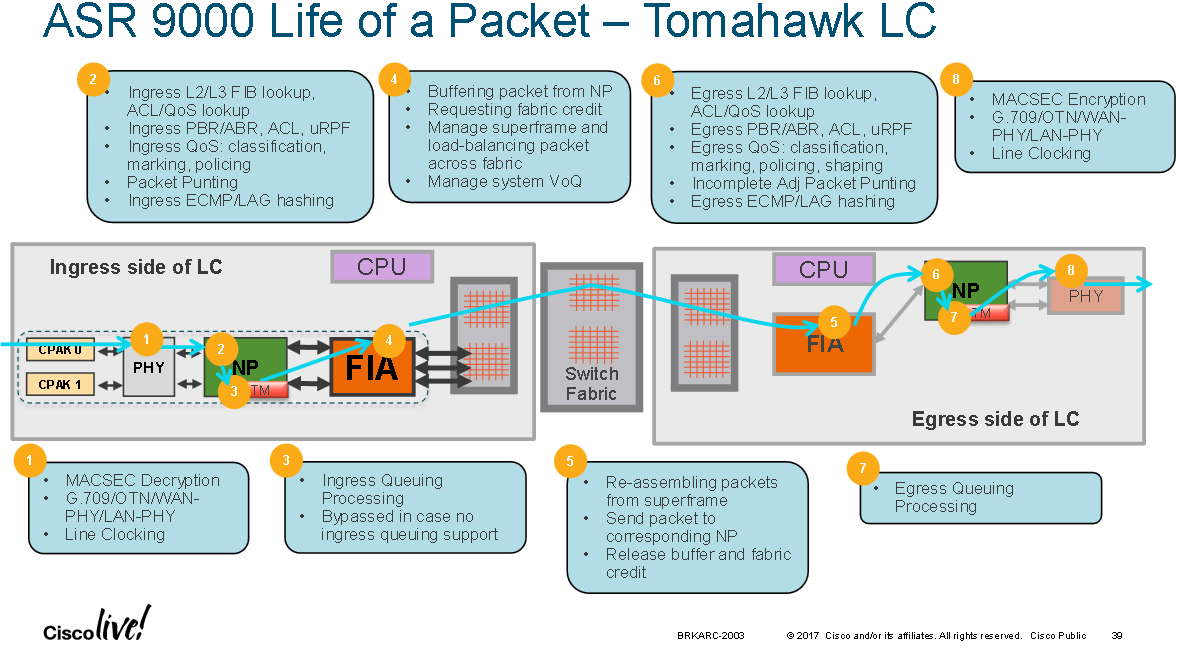
When packets enter the ingress NPU all ingress action are performed such as forwarding lookup, ACL, QoS, PBR, uRPF etc. Egress actions like the L2 re-write happen at the egress linecard NPU.
Unicast traffic through the switch [fabric] is managed by a VOQ (Virtual Output Queue) scheduler chip (the "arbiter"). The VOQ scheduler ensures that a buffer is available at the egress of the switch [fabric] to receive a packet before the packet can be sent into the switch [fabric]. This mechanism ensures that all ingress line cards have fair access to an egress card, no matter how congested that egress card may be [it's more granular than this, it ensure an ingress NP has access to an egress NP].
The VOQ mechanism is an overlay, separate from the switch fabric itself. VOQ arbitration does not directly control the switch fabric, but ensures that traffic presented to the switch [fabric] will ultimately have a place to go when it exits the switch [fabric], preventing congestion in the fabric.
The VOQ scheduler is also one-for-one redundant, with one VOQ scheduler chip (the arbiter) per RSP/RP.
Multicast traffic is replicated in the switch fabric. For multicast (including unicast floods), the Cisco ASR 9000 Series Routers replicate the packet as necessary at the divergence points inside the system, so that the multicast packets can replicate efficiently without having to burden any particular path with multiple copies of the same packet.
The switch fabric has the capability to replicate multicast packets to downlink egress ports. In addition, the line cards have the capability to put multiple copies inside different tunnels or attachment circuits in a single port.
There are 64-K Fabric Multicast Groups (RSP 2-based line cards) or 128-K Fabric Multicast Groups (RSP-440 and RSP-880 -based line cards) in the system, which allow the replication to go only to the downlink paths that need them, without sending all multicast traffic to every packet processor. Each multicast group in the system can be configured as to which line card and which packet processor on that card a packet is replicated to. Multicast is not arbitrated by the VOQ mechanism, but it is subject to arbitration at congestion points within the switch fabric.
The unicast packet forwarding path is: incoming interface PHY on LC--> NPU mapped to incoming interface on LC --> Bridge3 on LC (only if Trident) --> FIA on LC (queued via VOQ) --> Crossbar switch on RSP --> (ingress via virtual egress queue) FIA on LC ---> Bridge3 on LC (only if Trident) ---> NPU mapped to outgoing interface ---> Outgoing Interface PHY
The punt packet path is: incoming Interface PHY on LC --> NPU --> LC CPU --> NPU --> Bridge3 (if Trident) --> LC FIA --> RSP Crossbar --> Punt FPGA on RSP --> RSP CPU
Local interface ping path is: RSP CPU --> RSP FIA --> RSP Crossbar --> LC FIA --> LC CPU --> NP0 ---> LC FIA ---> Crossbar ---> RSP FIA ---> RSP CPU
The diagram below shows the packet path through a Tomahawk linecard:
The following diagram show the packet punt path for first generation Trident cards however it's mostly the same for Typhoon and Tomahawk cards too:
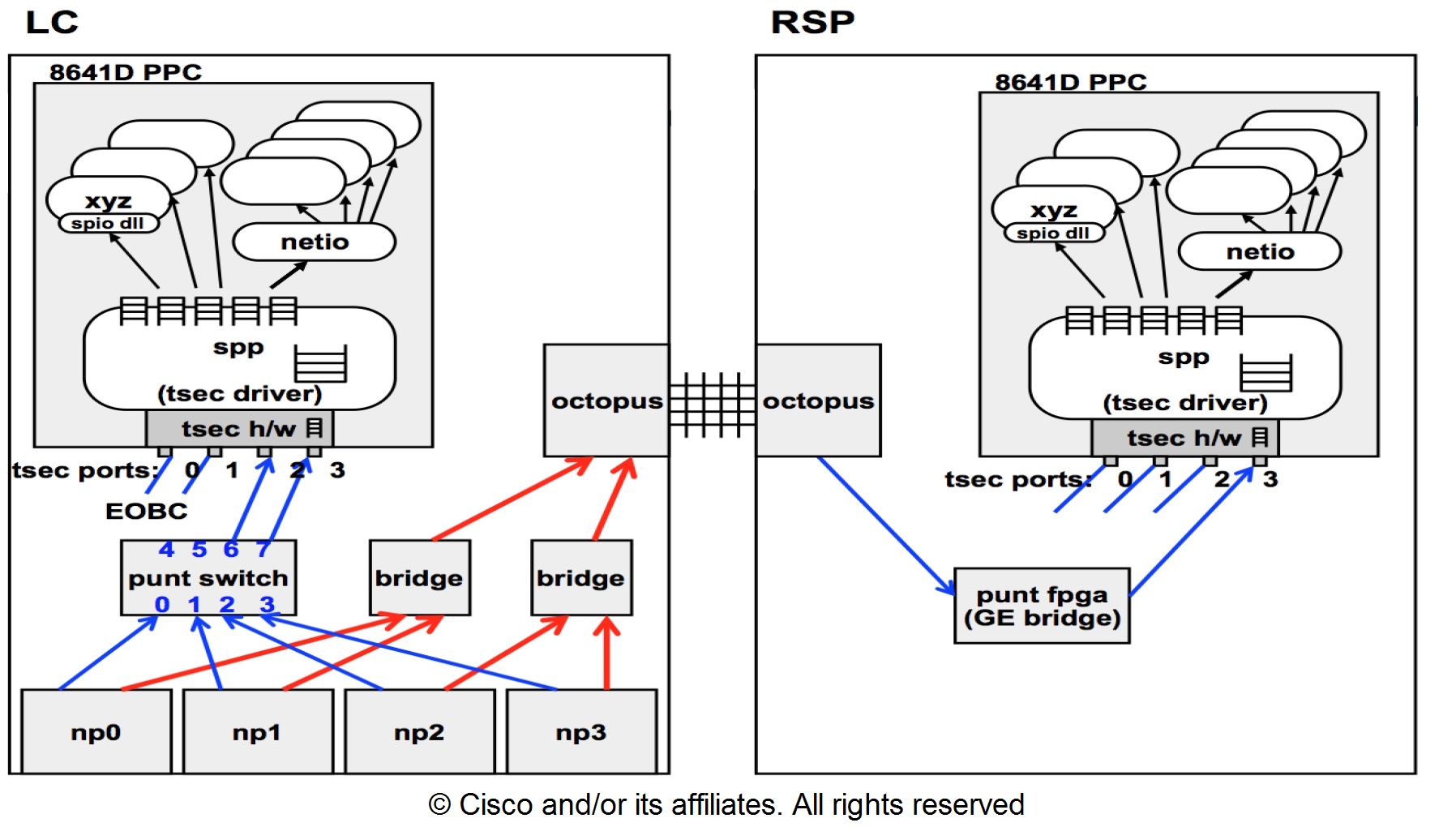
Virtual Output Queues and The Arbiter:
Each RSP/RP has two fabric chips which are both controlled by one common arbiter (dual RSPs/RPs means resilient arbiters per chassis). Only the arbiter on the active RSP/RP controls all four fabrics chips (assuming dual RSPs) however both arbiters are receiving the fabric access requests in order to know state of the whole system at any given time so that a failover between RSPs/RPs can be instantaneous. There is no keepalive between the arbiters but the RSPs/RPs have a CPLD (Complex Programmable Logic Device) ASIC (similar to an FPGA) and one of its functions is to track the other RSP/RP state via low level keepalives and establish which the active arbiter is.
Every Fabric Interconnect ASIC has a set of VOQs (Virtual Output Queues), this is a set of queues that represent a 10G entity in the system. Every 10G entity (10x1G ports on a single egress NP are represented with a single 10G VOQ in an ingress NP) has multiple priority classes. There are two strict priority queues and one normal queue (the fourth queue is for multicast and isn't used for unicast forwarding).
Generally the default queue starts to drop packets first during backpressure from the egress NP VOQs. Only when the egress NPU is getting overloaded (serving more Bps or PPS than the circuits can handle) will it start to exert backpressure to the ingress line card/NP. This is represented by a VOQ flow stalling on the FIA on that ingress line card.
When the ingress LC decides that it wants to send a particular packet to a particular egress NPU the MDF stage on the ingress LC encapsulated a packet with a fabric destination header. When the FIA looks at that "address", it checks the VOQ for the particular egress NPU/destination/LC and sees if there is enough bandwidth available. When it is ready to de-queue it to that LC, the ingress FIA requests a grant from the fabric (the arbiter) for that destination LC. The Arbitration algorithm is QOS aware, it ensures that P1 class packets have preference over P2 class and so on. The arbiter relays the grant request from the ingress FIA to the egress FIA.
The ingress FIA may group a multiple packets together going to that same egress LC into what is called a super frame. This means it is not native frames/packets that go over the switch fabric links but super frames. This is important to note because in a test of a constant 100pps, the CLI may show the fabric counters only reporting 50pps. This is not packet loss it would just mean that there are two packets in each super frame transmitting over the switch fabric. Superframes include sequencing information and destination FIAs support reordering (packets can be "sprayed" over multiple fabric links). Only unicast packets are placed into super-frames, never multicast ones.
Once the packet is received by the egress LC, the grant is returned is returned to the arbiter. The arbiter has a finite number of tokens per VOQ. When the arbiter permits the ingress FIA to send a (super)frame to a specific VOQ, that token is returned to the pool only when the egress FIA delivers the frames to egress NP. If the egress NP has raised a back-pressure signal to the egress FIA, the token remains occupied. This is how the arbiter eventually runs out of tokens for that VOQ in the ingress FIA. When that happens the ingress FIA will start dropping the incoming packets. The trigger for the back-pressure is the utilisation level of RFD buffers in an egress NP. RFD buffers are holding the packets while the NP microcode is processing them. The more feature processing the packet goes through, the longer it stays in RFD buffers.
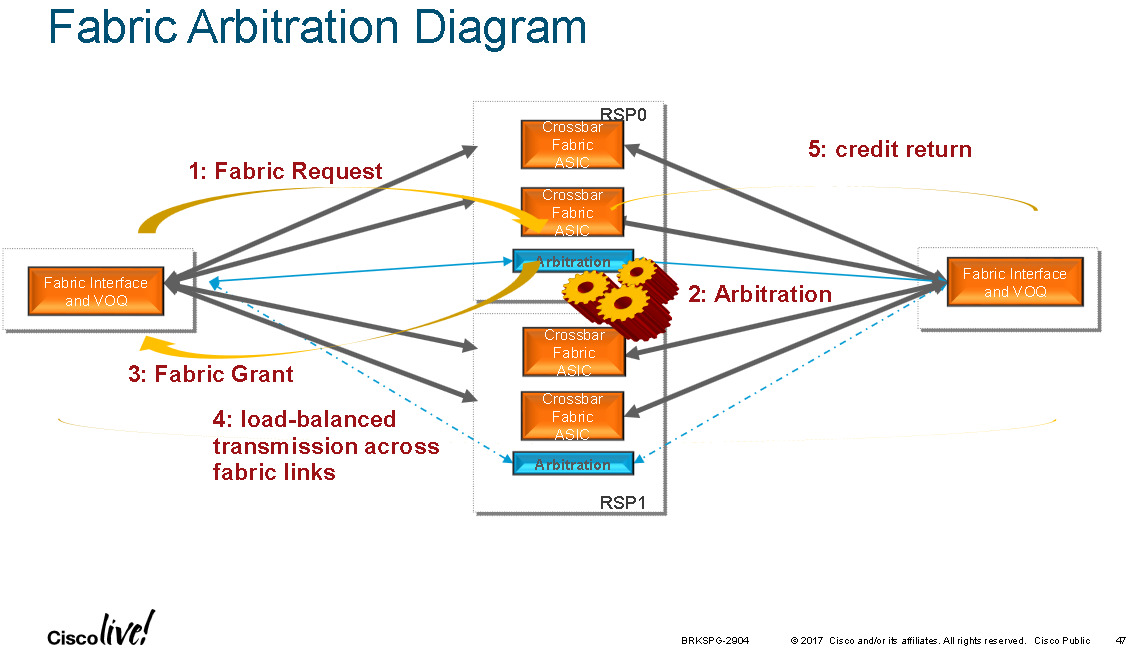
1. Ingress FIA makes fabric request to all chassis arbiters
2. Active arbiter checks for free access grant tokens and processes its QoS algorithm if congestion is present
3. Active arbiter sends fabric grant token to ingress FIA
4. Ingress FIA load-balances (super)frames over fabric links
5. Egress FIA returns a fabric token to the central arbiter
Virtual Output Queue Overview:
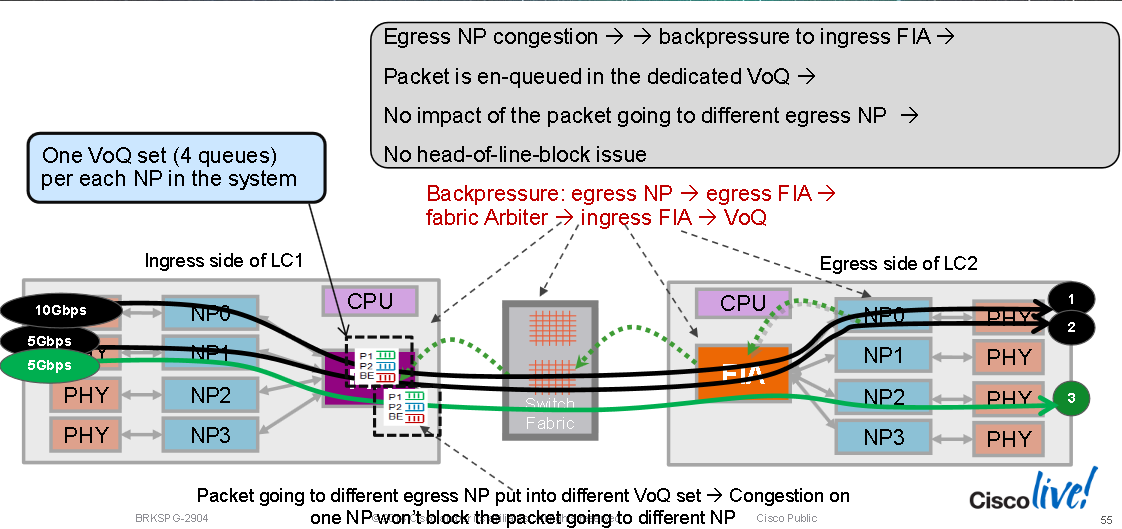
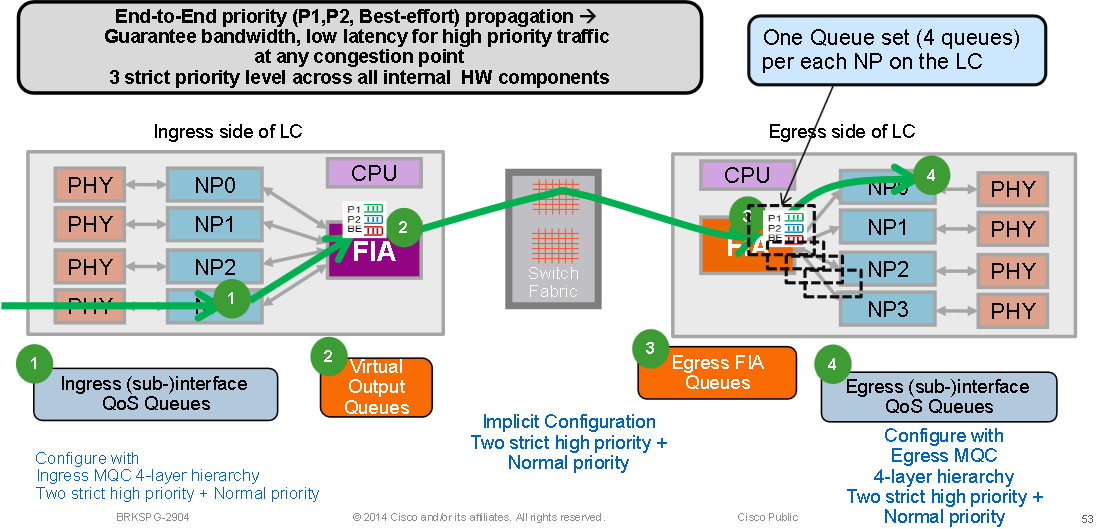
Fabric Interconnect ASIC VOQ Overview (example on chassis with 4x10G line cards):
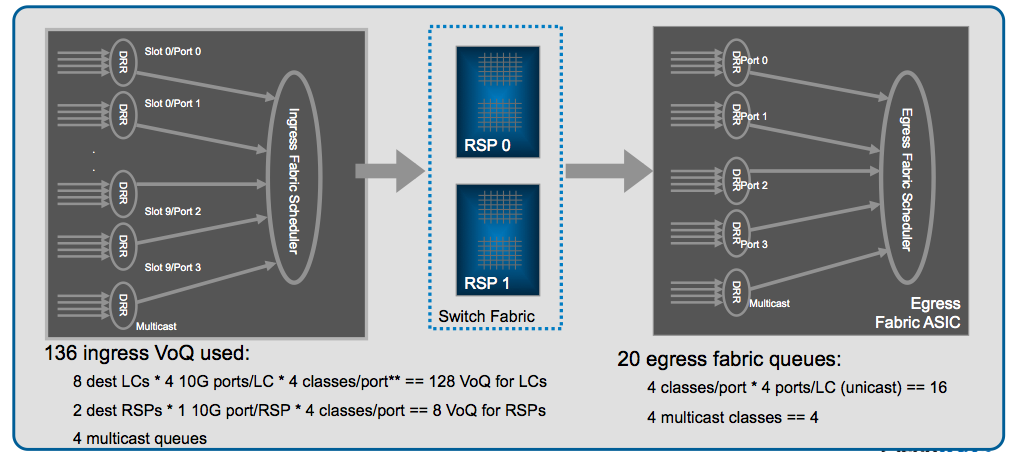
Fabric Arbitration Overview:
The original "Trident' NPU for the ASR9000 series (1st generation ASR9000 NPU) is the EZ-Chip NP3c model NPU which powers what are called the Ethernet Linecards for ASR9000 series routers. The NP3c is the EZ-Chip NPU used in 7600 ES+ line cards with beefed up buffers and CAMs for the ASR9000. The 2nd generation ASR9000 NPU called "Typhoon" are the EZ-Chip NP4c model NPU which power the Enhanced Ethernet Linecards for ASR9000 series routers. The 3rd generation of ASR9000 NPU also powering Enhanced Ethernet Linecards called "Tomahawk" uses the EZ-Chip NP5c model NPU.
Within a Typhoon NP there are 4 TOPs (task optimized processors) in the common four stage linear pipeline design to create a packet pipeline; a parse TOP, which feeds into the search TOP, which feeds into the resolve TOP, which finally feeds into the modify TOP.
Within Typhoon and Tomahawk NPs, ingressing packets from local ports are feed into the ICU. The ICU is the Internal Classification Unit. The ICU was added in Typhoon NPs as part of the pipeline processing (the TOPs pipeline), running as part of the microcode in the pipeline. In the Tomahawk NP the ICU is moved outside of the hardware forwarding pipeline stages for better performance (dedicated hardware with the EFD). The ICU & pre-parse process defines keys for fast lookups in search based memory.
Search/lookup memory which contains the FIB, MAC tables, adjacency tables is stored in RLDRAM for route/mac lookups and TCAM is used for matching VLAN tags, QoS and ACLs. The TCAM in the NP5c is a NetLogic 12000 unit, there is also DDR3 RAM in NP5c's but what is this for?
Each TOP inside the Typhoon NPU has the following memory structures: PRS (TopParse) > KMEM_LOW/KMEM_HIGH, SRCH (TopSearch) > LKP_KEY_MEM, RSV (TopResolve) > KMEM_LOW/KMEM_HIGH. Other memory blocks inside the Typhoon NPU: SMI > INT0_MEM to INT3_MEM, CAM_FIFO. TM_QC > FD_DRAM / QC_QD_DRAM.
Inside the Tomahawk NPU there is also the LKP2GRPS block which has HASH_LKP_KEY memory block. Tomahawk also has TM_QC > EMEM_PD_DRAM/IMEM_PD_DRAM.
The command "run; attach 0/0/CPU0; np_perf -e0 -R" will display packet drops happening in the ICU/pre-parse stage of NPU 0 on MPA 0.
CSCut98928: The buffers used in the ICU component are 'particalized'. It is analogous to ATM cells, a certain payload may require an extra cell, but only a small portion of that cell is actually used. This creates extra overhead (unused space) and in this case it takes a particle/buffer spot away that could be used for another packet. This is experienced as lower performance or higher drop count because lesser buffers are available at that high pps rate with that particular packet size.
The ICU is classifying incoming packets in the NP into ICFDQs (Input Classification Frame Descriptor Queues) based on the packet headers it pre-parses (packets egressing the pipeline leave via an OCFDQ, Output Classification Frame Descriptor Queue).
Inside the ICFDQs, EFD (Early Fast Discard) is a mechanism which looks at the queue before the packets enter the [TOPs] pipeline of the NPU. The EFD was software based with the ICU in Typhoon cards and has become hardware based with the ICU in Tomahawk cards.
The EFD can perform some minimalistic checking on precedence, EXP or CoS values to determine if a low or high priority packet is being processed. If the pipeline is clogged it can drop some lower priority packets to save the higher priority ones before they enter the pipeline by using Strict-priority Round-Robin.
These NP drop counters will show EFD drops "sh controllers np descriptions loc 0/0/cpu0 | i PRIORI". These NP counters will show drops relating to the TOPs pipeline: sh controllers np descriptions loc 0/0/cpu0 | i "PARSE|RSV|RESOLVE|MODIFY|MDF".
There are 64 ICFDQ groups the ICU can classifying packets into, each one supports 4 CoS queues. Network control traffic is CoS >= 6, high priority traffic is CoS = 5, low priority traffic is CoS < 5, the fourth queue is unused (multicast perhaps?).
PERSONAL SPECULATION: Are there 64 ICFDQ groups because there are 64 TOPs pipelines (Tomahawk only?), so the NP processes 64 packets in parallel? This output from a Typhoon NPU shows that it has 32 TOPresolve/TOPmodify/TOPparse engines and 8 TOPsearch engines but 24 search contexts. These Typhoon NPU registers group the TOPS parse registers into four groups.
On the Tomahawk NPU at the end of the TOPs pipeline there are two Traffic Managers that manage egress queueing, there is also one TM that manages ingress queueing. There is only one ingress and egress TM on the Typhoon NPU. The TM is a per NPU dedicated queue management ASIC. All user configured QoS is processed inside the NPU by the TM(s). Every physical port has a single default queue unless user configured QoS is applied.
Example of Tomahawk NP Achitecture:.png)
Upto IOS-XR version 6.0.1 the OS is a 32 bit QNX Unix variant. IOS-XR 6.1.1 is the first release based on 64 bit Linux (built on Wind River 7) called eXR "Evolved XR". From IOS-XR 6.0.1 Trident line cards are no longer supported. The NCS 5500, NCS 5000 and NCS1002 support 64 bit Linux based IOS-XR only but the ASR 9000 series routers support both 32 bit QNX and 64 bit Linux variants on platforms like the RSP880 (the ASR9001 for example which has a 32 bit freescale CPU only supports the 32 bit QNX variant of XR). 6.1.1 eXR (Linux) brings "Linux Containers" which are like BSD jails (VirutalMachines-as-a-Process) and support for 3rd party tools (bash, phython, tcpdump etc) and iPXE booting. An RSP880 and Tomahawk line cards only, mixing Tomahawk and Typhoon cards means classic 32 bit XR must be used.
Local Packet Transport Services:
LPTS supersedes the IOS CoPP paradigm. Traffic that can be handled on the local line card CPU (ARP, BFD, ICMP, NetFlow, OAM) rather than the RSP CPU is instructed to do so by LPTS. LPTS also dictates which packets must go to the RSP CPU (MGMT/control plane traffic, data plane traffic, Multicast, HSRP/VRRP). In either case LPTS is the CoPPs mechanism here protecting both LC and RSP CPU. LPTS policers work on a per NP basis so if the LPTS police value is set to 1000pps that means that every NP on the LC can punt with 1000pps to the RSP CPU or LC CPU. This is something to take into consideration when evaluating cards which have multiple NPU's per LC.
The LPTS maintains an iFIB (Internal FIB) which states which packets should go to the LC CPU or RSP CPU, at what rate (the policer value), and which packets should be completely dropped. This is stored in the LC NP to give wire-rate policing/protection. The iFIB contains dynamic ACLs automatically updated by user configuration, such as by configuring a BGP neighbour. Drop ACLs are pushed into TCAM, allowed flows come into the NP and are then policed and rate limited based on the iFIB.
MPP (Managed Plane Protection) can be used to allow or restrict inband managed traffic on standard line card interfaces, by default inband management is allowed on all line card interfaces. MPP configures the LPTS on a line card interface to enforce that inband management restriction.
! A BGP session is configured to remote peer 172.31.99.77 RP/0/RSP0/CPU0:ASR9001-XR5.3.3#show lpts pifib hardware entry brief location 0/0/CPU0 | i 172.31.98.77 37 IPV4 default TCP any LU(30) any,179 172.31.98.77,56133 126 IPV4 default TCP any LU(30) any,179 172.31.98.77,any ! Here we see it will be punted to the RSP CPU since this is an ASR9001 there are no LC CPUs RP/0/RSP0/CPU0:ASR9001-XR5.3.3#show lpts ifib optimized brief | i 172.31.98.77 BGP4 default TCP any 0/RSP0/CPU0 172.31.98.78,179 172.31.98.77,56133 BGP4 default TCP any 0/RSP0/CPU0 172.31.98.78,179 172.31.98.77 ! From the first set of output, the destination Local Unicast interface ID 30 ! This shows the slot mask 0x3 which in binary is chassis slots 0 & 1 (the rwo RSPs in this dual RSP system) RP/0/RSP0/CPU0:ASR9006-XR5.1.3#show lpts pifib optimized brief Type VRF-ID L4 Interface Deliver Local-Address,Port Remote-Address,Port ---------- -------- ------ ------------ ------------ -------------------------------------- ISIS default - any [0x0003] - -
Below are some outputs from CSCui29635 "OSPFv3 Shamlink is not up if core facing LC does not have VRF interface". In IOS-XR 4.3.4 and 5.1.0 it seems LPTS is blocking OSPF packets coming into a core facing interface when trying to configure an OSPF SHAM link back to another PE. OSPF is not configured on this core facing interface (Te0/0/2/1) however it is configured on another core facing interface (Te0/0/2/0) on the same NPU and since LTPS is operating at the NPU it is believe that they should be allowed into this interface (Te0/0/2/1).
! Te0/0/2/0 and Te0/0/2/1 are on the same NPU:
RP/0/RSP0/CPU0:ASR9001#show controllers np ports np0
Node: 0/0/CPU0:
----------------------------------------------------------------
NP Bridge Fia Ports
-- ------ --- ---------------------------------------------------
0 0 0 GigabitEthernet0/0/0/0 - GigabitEthernet0/0/0/19
0 0 0 TenGigE0/0/2/0, TenGigE0/0/2/1
! Te0/0/2/0 is allowing OSPFv2 packets but Te0/0/2/1 is not:
RP/0/RSP0/CPU0:ASR9001#show uidb data location 0/0/CPU0 Te0/0/2/0 ing-e | i OSPF
OSPFV2 LPTS Opt Flag 0x1
OSPFV3 LPTS Opt Flag 0x0
RP/0/RSP0/CPU0:ASR9001#show uidb data location 0/0/CPU0 Te0/0/2/1 ing-e | i OSPF
OSPFV2 LPTS Opt Flag 0x0
OSPFV3 LPTS Opt Flag 0x0
! Since this is an ASR9001 which is collapsed chassis design, there are no line card CPUs, so control plane traffic is punted to the central RSP after LTPS in the NPU has approved it. Below it can be seen that OSPF is permitted in "any" interface to "LU(30)" which is the RSP:
RP/0/RSP0/CPU0:ASR9001#show lpts pifib hardware entry brief location 0/0/CPU0 | i OSPF
9 IPV4 * OSPF any LU(30) 100.103.13.1,any 100.103.12.1,any
14 IPV4 * OSPF Optimized LU(30) 224.0.0.5,any any,any
15 IPV4 * OSPF Optimized LU(30) 224.0.0.6,any any,any
18 IPV4 * OSPF Optimized LU(30) any,any any,any
254 IPV4 * OSPF any LU(30) any,any any,any
255 IPV4 * OSPF any LU(30) 224.0.0.5,any any,any
256 IPV4 * OSPF any LU(30) 224.0.0.6,any any,any
274 IPV4 * OSPF any LU(30) any,any any,any
9 IPV6 * OSPF any LU(30) ff02::5,any any,any
10 IPV6 * OSPF any LU(30) ff02::6,any any,any
26 IPV6 * OSPF any LU(30) any,any any,any
RP/0/RSP0/CPU0:ASR9001#show lpts ifib optimized brief | i OSPF
OSPF4 * OSPF any 0/RSP0/CPU0 100.103.13.1 100.103.12.1
OSPF4 default OSPF any 0/RSP0/CPU0 any any
OSPF4 * OSPF any 0/RSP0/CPU0 any any
OSPF_MC4 default OSPF any 0/RSP0/CPU0 224.0.0.5 any
OSPF_MC4 * OSPF any 0/RSP0/CPU0 224.0.0.5 any
OSPF_MC4 default OSPF any 0/RSP0/CPU0 224.0.0.6 any
OSPF_MC4 * OSPF any 0/RSP0/CPU0 224.0.0.6 any
There are several issues with LPTS though, it is not a panacea:
- LPTS works at the NPU level; With two (or more) interfaces that share the same NPU and one of which is used to connect to an IXP for example, the LPTS policer may need to be raised for BGP due to the high number of BGP sessions established over a single interface. This raises the "allowed" BGP packets in via both the IXP facing interface on this NPU and the non-IXP facing interface(s) attached to the same NPU.
- Also in the case that attack traffic is coming in via interface X to NPU Y, a flood of TCP packets to port 179 faking a BGP session for example, if the NPU BGP pps rate limit is exceeded an attacker can cause BGP sessions on other interfaces "protected" by NPU1 to drop as the BGP pps rate limit for the NPU service those interfaces is exceeded.
- Packets punted by LPTS to the LC/RSP CPU are not subject to MQC meaning that QoS policies cannot be used on the interface level rate limit ICMP or BGP etc. An ACL can be applied to an interface to filter traffic at the interface level, such as filtering LDP traffic for example, on an interface that definitely doesn't need to send/receive LDP traffic. This can be used when the interface is served by the same NPU as another interface which does need to process LDP traffic. However this is a hard "on/off" solution. It can't be used on interfaces that need LDP to rate-limit LDP traffic at the interface level.
The ASR9000s and CSR devices support LPTS EFT (Excessive Flow Trap) to address the issue of a single "bad actor" using the entire pps budget of an NPU and starving all interfaces server by that NPU. This is the description from the Cisco docs:
The Excessive Punt Flow Trap feature monitors control packet traffic arriving from physical interfaces, sub-interfaces, bundle interfaces, and bundle sub-interfaces. If the source that floods the punt queue with packets is a device with an interface handle, then all punts from that bad actor interface are penalty policed.
The EPFT feature supports policing the bad actors for Address Resolution Protocol (ARP). ARP has a static punt rate and a penalty rate. For example, the sum total of all ARP punts from remote devices is policed at 1000 packets per second (pps) to the router's CPU. If one remote device sends an excessive rate of ARP traffic and is trapped, then ARP traffic from that bad actor is policed at 10 pps. The remaining (non-bad) remote devices continue to use the static 1000 pps queue for ARP. The excessive rate required to cause an interface to get trapped has nothing to do with the static punt rate (for example, 1000 pps for ARP). The excessive rate is a rate that is significantly higher than the current average rate of other control packets being punted. The excessive rate is not a fixed rate, and is dependent on the current overall punt packet activity.
Previous page: ASR9000 NP Packet Capture
Next page: ASR9000v / IOS-XRv