Date created: Saturday, July 23, 2016 11:01:27 AM. Last modified: Monday, June 10, 2024 12:23:05 PM
Forwarding Hardware
References:
http://www.cisco.com/networkers/nw04/presos/docs/RST-2311.pdf
https://en.wikipedia.org/wiki/Content-addressable_memory#Ternary_CAMs
http://www.firstpr.com.au/ip/sram-ip-forwarding/router-fib/#Cisco_others_TCAM
http://www.cisco.com/c/dam/global/sr_rs/assets/events/expo_08/pdfs/Arhitektura_C7600_Aleksandar_Vidakovic.pdf
https://supportforums.cisco.com/document/63276/acl-tcam-and-lous-catalyst-6500
BRKARC-2350 - IOS Routing Internals (2013)
Inside Cisco IOS Software Architecture
Contents:
Linear Lookups
CAM vs TCAM vs RAM
Cisco TCAM Specifics
Cisco EARL (TCAM)
Task Optimised Processors (TOPs)
A standard ACL consisting of N ACEs will take O(n) time to read every entry linearly. Using compiled ACLs hashing the packet to generate a table lookup ID for a table of stored hashed ACEs provides O(1) lookup time:
The same performance limitation applies to forwarding lookups if a flat prefix list is used, O(n), in the case that the list is "ordered" circa 50% of lookups would match no later than half way through the table to give an average upper bound of O(n/2):
Using a binary trie for forwarding lookups instead of a flat table improves efficiency by cutting out 50% of the tree branches, the initial tree root will be 0 or 1, and so on down the trie, producing O(log(n)) for the upper bound: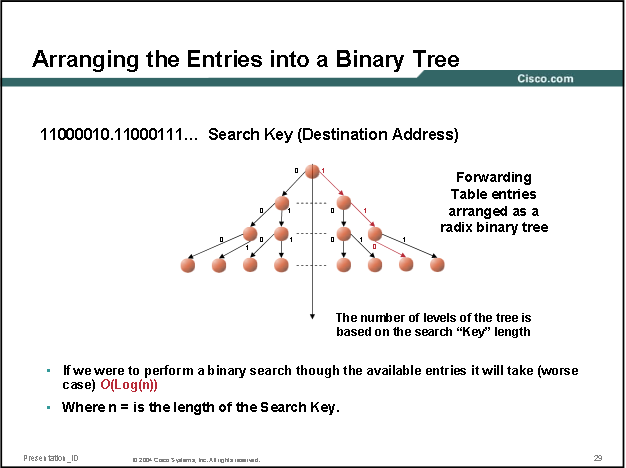
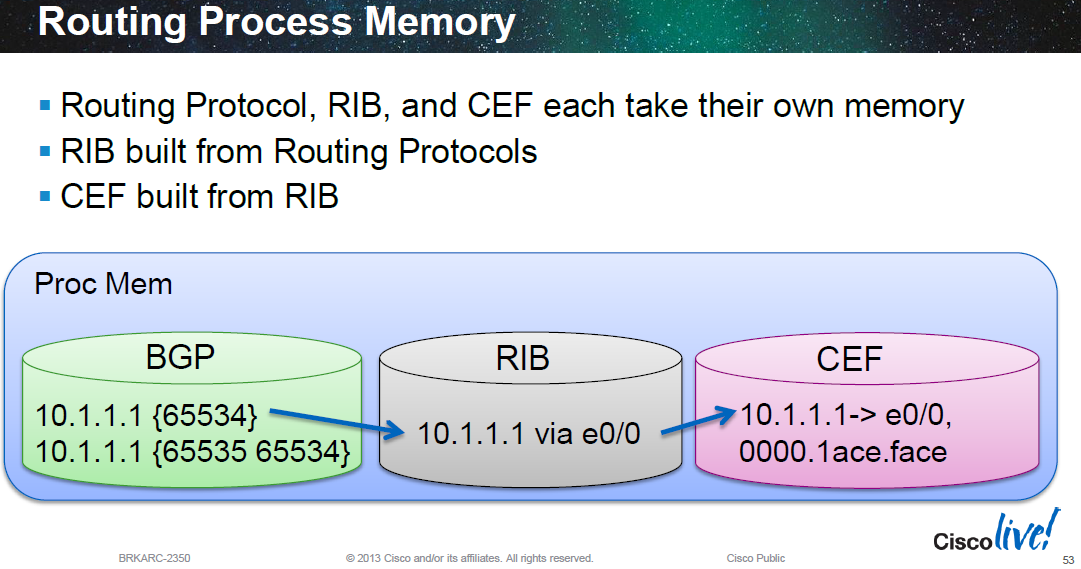
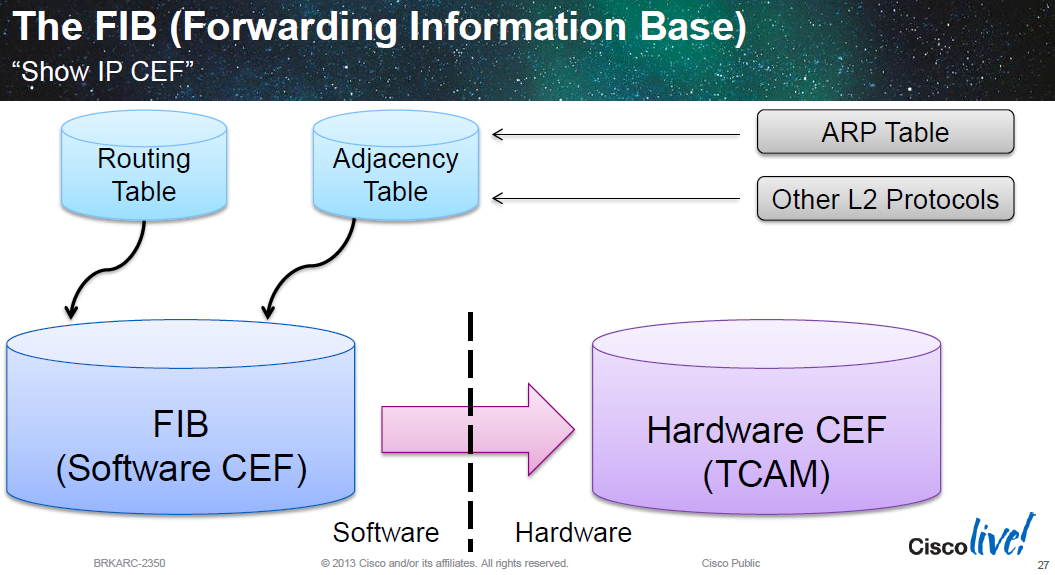
Cisco devices with distributed control plane and forwarding planes (6500/7600s, Nexus 7000s, ASR9000s etc) take routing information from multiple protocols (administrative distance is the tie breaker amongst protocols offering the same route) and build a RIB in software. The RIB contains the next hop (the RIB is usually a hash index table). The route with next hop info, egress interface info and egress layer 2 rewrite info is all built into the FIB which sits in memory (software CEF, often as a trie) which means all the required forwarding information is provided in a single lookup to the FIB. The FIB is then programmed into hardware (hardware CEF) in TCAMs for line rate lookups in high end routers.
Cisco uses a proprietary form of trie code to create what they call call M-Tries (for the software FIB/software CEF tables). Many Cisco routers that use m-tries use 256-way mtrie structures (with each node having 256 children, so after 4 "levels" all 2^32 bit IPv4 addresses are covered), the child of each of the final octet nodes is CEF adjacency table entry (next hop details) for that node (IP route):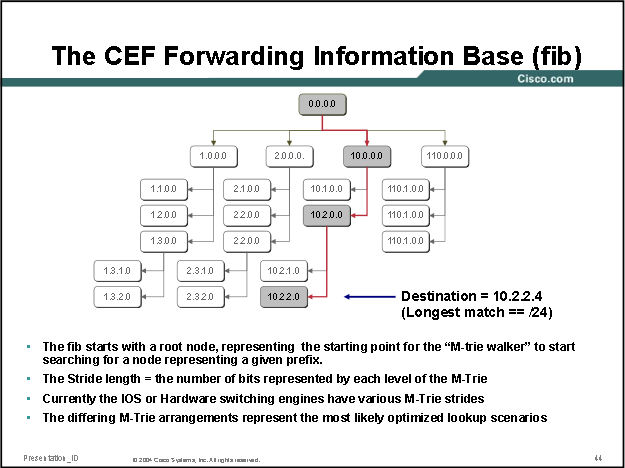
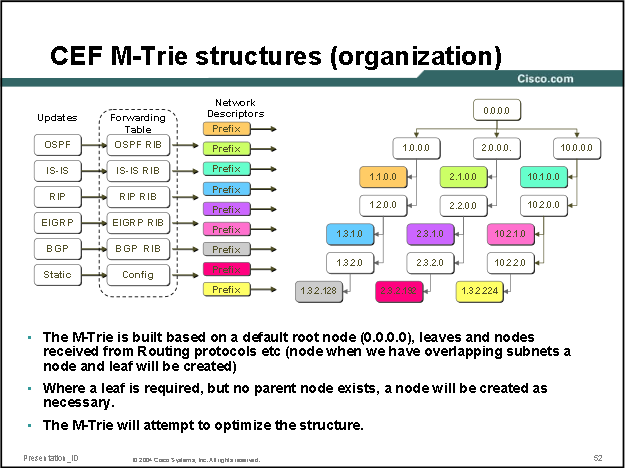

In the output below we can see a Cisco ASR920 is using a stride pattern of 8-8-8-8 for it's MTRIE:
ASR920#show ip cef tree Table Default tree information: MTRIE/RTREE storing IPv4 addresses 21 entries (21/0 fwd/non-fwd) Forwarding tree: Forwarding lookup routine: IPv4 mtrie 8-8-8-8 optimized 69 inserts, 48 deletes 8-8-8-8 stride pattern short mask protection enabled for <= 4 bits without process suspension 21 leaves (588 bytes), 22 nodes (22880 bytes) 25132 total bytes leaf ops: 69 inserts, 48 deletes leaf ops with short mask protection: 4 inserts, 2 deletes per-prefix length stats: lookup off, insert off, delete off refcounts: 5686 leaf, 5632 node node pools: pool[C/8 bits]: 22 allocated (0 failed), 22880 bytes Non-Forwarding tree: 115 inserts, 115 deletes 0 leaves (0 bytes), 0 nodes (0 bytes) 0 total bytes
Content-addressable memory (CAM) is a special type of computer memory used in certain very-high-speed searching applications. It compares input search data against a table of stored data, and returns the address of matching data (or in the case of associative memory, the matching data). Unlike standard computer memory (RAM) in which the user supplies a memory address and the RAM returns the data word stored at that address, a CAM is designed such that the user supplies a data word and the CAM searches its entire memory to see if that data word is stored anywhere in it. If the data word is found, the CAM returns a list of one or more storage addresses where the word was found (and in some architectures, it also returns the contents of that storage address, or other associated pieces of data). Thus a CAM is the hardware embodiment of what in software terms would be called an associative array.
Because a CAM is designed to search its entire memory in a single operation, it is much faster than RAM in virtually all search applications. There are cost disadvantages to CAM however. Unlike a RAM chip, which has simple storage cells, each individual memory bit in a fully parallel CAM must have its own associated comparison circuit to detect a match between the stored bit and the input bit. Additionally, match outputs from each cell in the data word must be combined to yield a complete data word match signal. The additional circuitry increases the physical size of the CAM chip which increases manufacturing cost. The extra circuitry also increases power dissipation since every comparison circuit is active on every clock cycle. Consequently, CAM is only used in specialized applications where searching speed cannot be accomplished using a less costly method. To achieve a different balance between speed, memory size and cost, some implementations emulate the function of CAM by using standard tree search or hashing designs in hardware, using hardware tricks like replication or pipelining to speed up effective performance.
Binary CAM is the simplest type of CAM which uses data search words consisting entirely of 1s and 0s. Ternary CAM (TCAM) allows a third matching state of "X" or "don't care" for one or more bits in the stored data word, thus adding flexibility to the search. For example, a ternary CAM might have a stored word of "10XX0" which will match any of the four search words "10000", "10010", "10100", or "10110". The added search flexibility comes at an additional cost over binary CAM as the internal memory cell must now encode three possible states instead of the two of binary CAM. This additional state is typically implemented by adding a mask bit ("care" or "don't care" bit) to every memory cell.
Ternary CAMs are often used in network devices, where each address has two parts: the network address, which can vary in size depending on the subnet configuration, and the host address, which occupies the remaining bits. Each subnet has a network mask that specifies which bits of the address are the network address and which bits are the host address. Routing is performed by consulting a routing table maintained by the device which contains each known destination network address, the associated network mask, and the information needed to route packets to that destination. Without CAM, the router compares the destination address of the packet to be routed with each entry in the routing table, performing a logical AND with the network mask and comparing it with the network address. If they are equal, the corresponding routing information is used to forward the packet. This is a basic LPM match which gives an upper bound of O(n). Using a ternary CAM for the routing table makes the lookup process very efficient. The addresses are stored using "don't care" for the host part of the address, so looking up the destination address in the CAM immediately retrieves the correct routing entry; both the masking and comparison are done by the CAM hardware. This works if (a) the entries are stored in order of decreasing network mask length, and (b) the hardware returns only the first matching entry; thus, the match with the longest network mask (longest prefix match) is used but much faster than iterating through a flat table.
Updates to TCAM hardware can be expensive for the CPU though because the TCAM efficiency heavily relies or prefix information being stored in order.
The TCAMs often return a result which is a location in SRAM, the location in SRAM stores the egress interface details (or alternatively an internal punt interface ID or drop interface ID) and the rewrite information for the egress path. SRAM is significantly faster than DRAM (its is the typical kind of RAM used for CPU caches) and doesn't need refershing but this means that both TCAM and SRAM are expensive with regards to manufactoring costs and power consumption. This in turn means that even though "memory is cheap" an RSP720-3CXL for a Cisco 7600 chassis, has a fixed 1 million IPv4 limit in TCAM/SRAM, the Cisco ASR9001 has a 4 million IPv4 prefix TCAM limit.
Various Cisco products (6500/7600, ASR9000s) use TCAM forwarding and can use multiple TCAMS, one for FIB (packet forwarding lookups), one for ACLs (packet filtering lookups), one for QoS rules, and so on. The ASR9000 1st and 2nd generation line cards uses the EZchip NP-3C ASICs for forwarding lookups (with external RAM, more detail below/here) and the 3rd generation line cards use the Broadcom Tomahawk ASIC. Various Juniper routers don't use TCAMs, the M120 and MX960 both instead uses a chip called the I-chip with RLDRAM ("Reduced Latency" RAM which is faster than DRAM but slower than SRAM). Some Juniper switches however like the EXs use Marvell chips for TCAM like operations.
Juniper also have the Trio chip set for the MX range (I-Chip/DPC cards being phased out, DPCE too?) which like the I-Chip use external RLDRAM. The Trio chipset contains a "Lookup Block". A key feature in the Lookup Block is that it supports Deep Packet Inspection (DPI) and is able to look over 256 bytes into the packet. As packets are received by the Buffering Block, the packet headers are sent to the Lookup Block for additional processing. All processing is completed in one pass through the Lookup Block regardless of the complexity of the workflow. Once the Lookup Block has finished processing, it sends the modified packet headers back to the Buffering Block to send the packet to its final destination. In order to process data at line rate, the Lookup Block has a large bucket of reduced-latency dynamic random access memory (RLDRAM) that is essential for packet processing.
RAM typically stores data in single octet cells that are usually individually addressable. A four byte integer is stored in four continuous cells in RAM for example. TCAM tends to stored data in fixed blocks that are large enough to store an entire route in one block or "cell". Typical sizes are 72 bits on the RSP720 & ES+ NP-3C for 7600s (L2 TCAM on the Superman ASIC) and Wahoo TCAM on 12000's, double sized blocks (144 bits) are used for IPv6 and multicast routing entries on these platforms (288 bits blocks are even used on the Wahoo TCAM), ASR920's use 80 bit blocks on the Cylon ASIC TCAM and again 80 bit blocks/cells on the NILE ASIC TCAM in ME3600X/ME3800X. Each block of e.g. 72 bits/9 bytes (or whatever size is used) falls under a single address to read from. 72-bit TCAM blocks are 8 byte (64-bit) blocks + 1 byte of parity. Thus 144-bit blocks are 2x 8 byte blocks each with 1 byte of parity, etc.


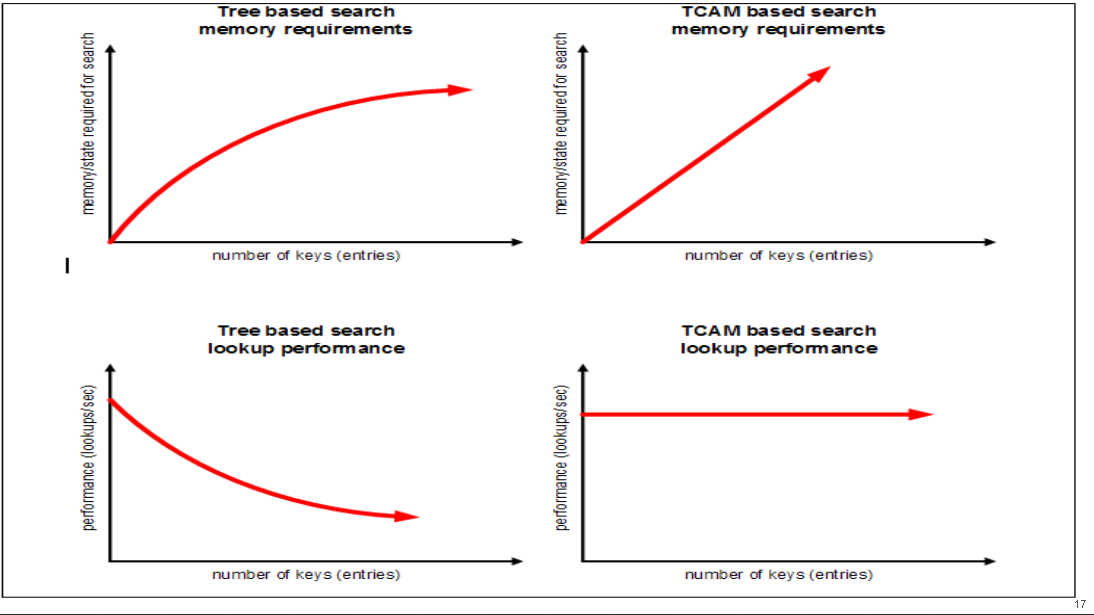
Neither TCAMs or Tries in RLDRAM/SRAM are a better solution than the other, they offer different performance advantages in different scenarios:

Because Cisco use a funnelling approach of protocol RIBs feeding into a central RIB, which is then compiled into a FIB with the forwarding and adjacency information included, which is then programmed into a hardware TCAM; learning the same routes from multiple sources doesn't increase usage within the TCAM. For example 3 eBGP peers sending the same routes into the BGP RIB, BGP will chose the single best path amongst the three to offer into the central RIB. And/or if other protocols are offering the same routes into the central RIB, only the single best path is chosen. This is compiled into the FIB and programmed into hardware. This is shown in the diagram below:
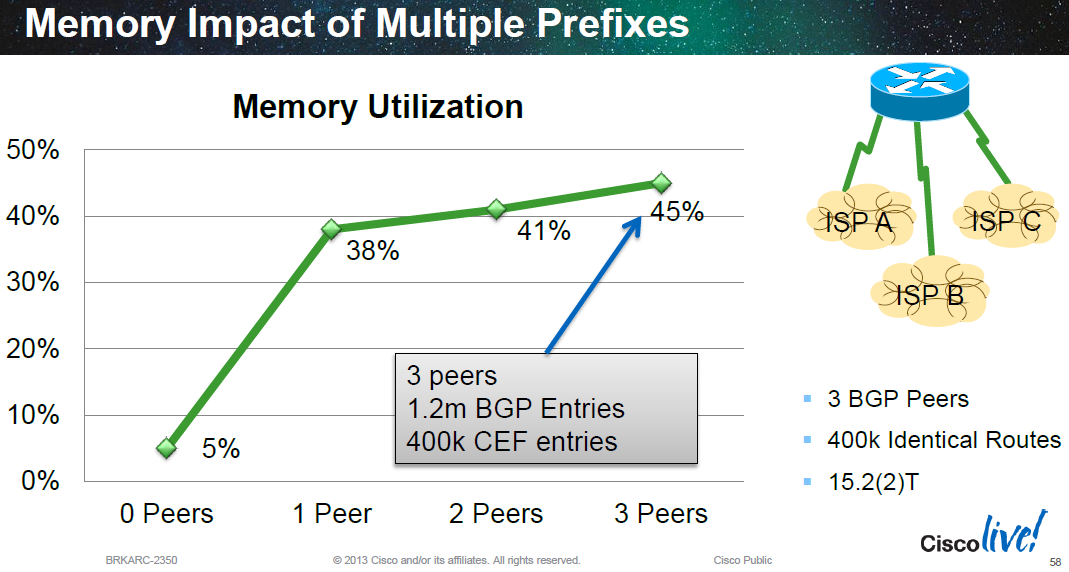
Exceptions to this include bonded links at layer 2 (LACP etc) and (un-)ECMP at layer 3 (BGP multipath etc). In these cases where multiple forwarding paths exist a hash function is used to return a different result from the TCAM in each lookup (by adding some variance to the lookup key).
A mixture of TCAM and Tree memory is very typical using TCAMs for ACls and QoS and Trees for forwarding:

Since TCAM scaling is costly compared to using a software algorithms (like hashing, tries, LPM etc) some vendors mix the methods, Cisco for example implement their M-Trie in hardware:
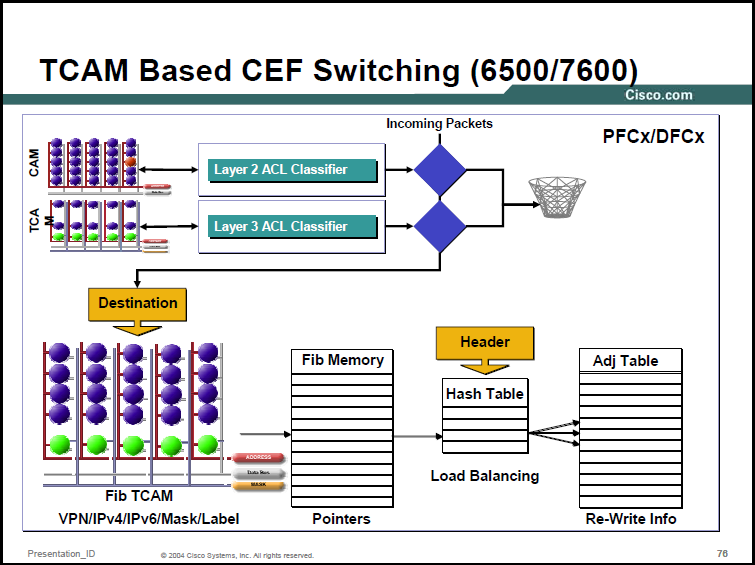
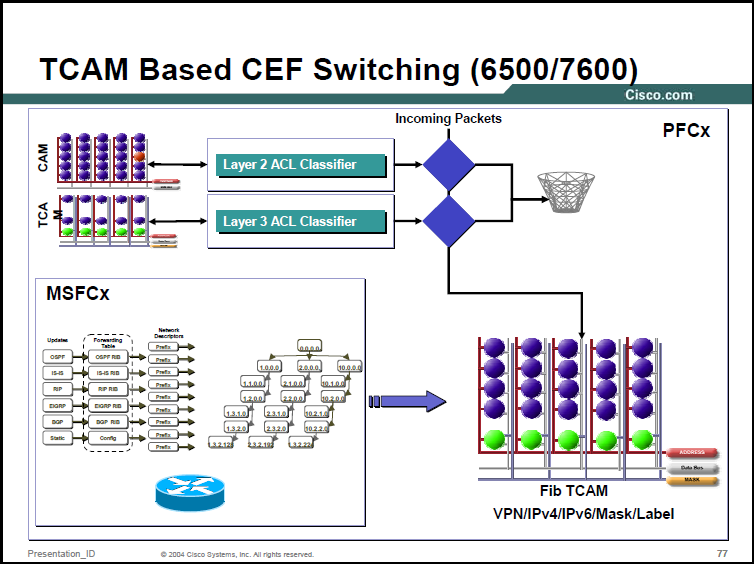
Cisco often use TCAMs for ACL and QoS lookups. In this example the Cisco 6500/7600 TCAM is explored. For ACLs inside TACM on a 6500/7600 the TCAM is split into Masks and Values. A value is an ACE which usually contains the source IP address, destination IP address, IP protocol number, source port and destination port (other values are supported depending on the TCAM in use). The Mask is a bitmask (like a subnet mask in IP addressing) which says which parts of the Value needed to be checked.
For example, assume the Value is 0x0A000001 0x00000000 0x06 0x0000 0x0000 (the field order is as above so the source IP here is 10.0.0.1 to 0.0.0.0 which is any destination, IP protocol 0x06 is TCP and 0x0000 is any source and destination port). The mask is a 104 bit field (the Value field is 13 bytes long), if this ACL entries wants to match a source IP of 10.0.0.1 to any destination where the IP protocol is TCP the Mask value should be 0xFFFFFFFF 0x000000 0xFF 0x0000 0x0000.
In the 6500/7600 specifically, for each Mask eight Values can be assigned. Each value has its own Result (permit or deny for example). This helps to compress ACEs with matching properties (six ACEs that allow TCP port 25 from the Internet to six different individual internal host IPs would all have the same Mask, each mask would have its own result, and they would all be permit in this case).
The TCAM also supports Logical Operation Units (LOUs) which can be logical conditions like greater than, equal to, less than, not equal to or within a specific range (again the available instructions varies by TCAM). 6500 TCAM has 128 hardware LOUs which are a shared global resource to store values used in LOUs in more complex ACEs (like a port range statement, "TCP port equal to/greater than 25 and less than/equal to 30"). The LOUs are also used for matching TCP flags.
The 128 LOUs in the 6500 TCAM are divided in half for source and destination port operations and 2 LOUs are need to match a port range, so in total 32 source port ranges and 32 destination port ranges can be programmed into the hardware (this is total aggregate across all ACLs, not across ACEs within a single ACL). For the 6500/7600 any single ACL can use a maximum of 10 LOUs.
If there are more port ranges in the ACL than the available LOUs and L4OPs they are expanded in software into equivalent entries. This is known as PORT EXPANSION.
In the below outputs from two different Cisco 6500 series setups, the TCAM entries and SRAM references can be seen for ACL entries and IPv4 forwarding rules:
! Cisco 6513 Non-E-Chassis with SUP720, WS-X6748-GE-TX using DFC3B
6513#show mod
Mod Ports Card Type Model Serial No.
--- ----- -------------------------------------- ------------------ -----------
2 6 Firewall Module WS-SVC-FWM-1 XXXXXXXXXXX
3 1 Application Control Engine Module ACE30-MOD-K9 XXXXXXXXXXX
7 2 Supervisor Engine 720 (Active) WS-SUP720-3B XXXXXXXXXXX
9 48 CEF720 48 port 10/100/1000mb Ethernet WS-X6748-GE-TX XXXXXXXXXXX
10 4 CEF720 4 port 10-Gigabit Ethernet WS-X6704-10GE XXXXXXXXXXX
Mod Sub-Module Model Serial Hw Status
---- --------------------------- ------------------ ----------- ------- -------
3 ACE Expansion Card 1 ACEMOD-EXPN-DC XXXXXXXXXXX 1.1 Ok
3 ACE Expansion Card 2 ACEMOD-EXPN-DC XXXXXXXXXXX 1.1 Ok
7 Policy Feature Card 3 WS-F6K-PFC3B XXXXXXXXXXX 2.3 Ok
7 MSFC3 Daughterboard WS-SUP720 XXXXXXXXXXX 2.6 Ok
9 Distributed Forwarding Card WS-F6700-DFC3B XXXXXXXXXXX 4.9 Ok
10 Centralized Forwarding Card WS-F6700-CFC XXXXXXXXXXX 4.2 Ok
6513#show tcam counts
Used Free Percent Used Reserved
---- ---- ------------ --------
Labels:(in) 6 4066 0 24
Labels:(eg) 1 4071 0 24
ACL_TCAM
--------
Masks: 94 4002 2 72
Entries: 79 32689 0 576
QOS_TCAM
--------
Masks: 34 4062 0 25
Entries: 42 32726 0 200
LOU: 0 128 0
ANDOR: 0 16 0
ORAND: 0 16 0
ADJ: 3 2045 0
6513#show platform hardware capacity acl
ACL/QoS TCAM Resources
Key: ACLent - ACL TCAM entries, ACLmsk - ACL TCAM masks, AND - ANDOR,
QoSent - QoS TCAM entries, QOSmsk - QoS TCAM masks, OR - ORAND,
Lbl-in - ingress label, Lbl-eg - egress label, LOUsrc - LOU source,
LOUdst - LOU destination, ADJ - ACL adjacency
Module ACLent ACLmsk QoSent QoSmsk Lbl-in Lbl-eg LOUsrc LOUdst AND OR ADJ
7 1% 2% 1% 1% 1% 1% 0% 0% 0% 0% 1%
9 1% 2% 1% 1% 1% 1% 0% 0% 0% 0% 1%
6513-dfc9#show tcam details acl
ACL_TCAM
Lbl DestAddr SrcAddr Dpt Spt L4OP TOS Frag More prot type bank lkup Rec Xtag Mpls Rslt/Cnt
17818 Entry : 1 10.192.1.0 0.0.0.0 0 0 0 0 0 0 0 0 0 1 0 0 0 C0080003
17819 Mask : 4095 255.255.255.0 0.0.0.0 0 0 0 0 0 0 F 0 0 1 0 0 0 1
! Cisco 6506-E chassis, SUP2T, WS-X6816-10GE with DFC4...
6506-E#show mod
Mod Ports Card Type Model Serial No.
--- ----- -------------------------------------- ------------------ -----------
1 16 CEF720 16 port 10GE WS-X6816-10GE XXXXXXXXXXX
2 48 CEF720 48 port 10/100/1000mb Ethernet WS-X6748-GE-TX XXXXXXXXXXX
3 3 ASA Service Module WS-SVC-ASA-SM1 XXXXXXXXXXX
4 6 Firewall Module WS-SVC-FWM-1 XXXXXXXXXXX
6 5 Supervisor Engine 2T 10GE w/ CTS (Acti VS-SUP2T-10G XXXXXXXXXXX
Mod Sub-Module Model Serial Hw Status
---- --------------------------- ------------------ ----------- ------- -------
1 Distributed Forwarding Card WS-F6K-DFC4-EXL XXXXXXXXXXX 1.2 Ok
2 Centralized Forwarding Card WS-F6700-CFC XXXXXXXXXXX 3.1 Ok
3/0 ASA Application Processor SVC-APP-PROC-1 XXXXXXXXXXX 1.0 Ok
6 Policy Feature Card 4 VS-F6K-PFC4XL XXXXXXXXXXX 3.0 Ok
6 CPU Daughterboard VS-F6K-MSFC5 XXXXXXXXXXX 3.0 Ok
6506-E#remote login module 1
6506-E-dfc1#show platform hardware acl lou
Dumping h/w lou values
Index lou_mux_sel A_Opcode A_Value B_Opcode B_Value
----- ----------- -------- ------- -------- -------
0 7 NEQ 0 NEQ 0
1 0 NEQ 0 NEQ 0
2 0 NEQ 0 NEQ 0
....
6506-E-dfc1#show platform hardware acl tcam
----------------------------------------------------------------------------------------------------------------------------------------
ENTRY TYPE:
A - ARP I - IPv4 M - MPLS O - MAC Entry S - IPv6(Six) C - Compaction L - L2V4
Suffix: D - dynamic entry E - exception entry R - reserved entry
FIELDS:
FS - first_seen/from_rp ACOS - acos/group_id F - ip_frag FF - frag_flag
DPORT - dest_port SPORT - src_port LM - L2_miss GP - gpid_present
ETYPE - enc_etype CEVLD - ce_vlan_valid MM - mpls_mcast FN - exp_from_null
IV - ip_hdr_vld MV - mpls_valid E_CAU - exception_cause UK - U_key
ACO - acos A/R - arp_rarp RR - req_repl GM - global_acl_fmt_match
D-S-S-A - dest_mac_bcast, src_snd_mac_same, snd_tar_mac_same, arp_rarp_vld OM - ofe_mode
SVLAN - Src_vlan
----------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------------------------
I INDEX LABEL FS ACOS AS IP_SA IP_DA L4OP F FF L4PROT DPORT SPORT RSLT CNT
S INDEX LABEL FS ACOS AS IPV6_SA_ID IPV6_DA_ID L4OP F FF L4PROT DPORT SPORT RSLT CNT
C INDEX IPV6_ADDR RSLT CNT
O INDEX LABEL FS ACOS LM GP ETYPE SRC_MAC DEST_MAC CEVLAN CEVLD DSCP_ID RSLT CNT
A INDEX LABEL A/R RR IP_SA IP_DA SRC_MAC D-S-S-A GM LM OM RSLT CNT
M INDEX LABEL ACOS GP FS MM EXP_0 FN MPLS_LABEL EXP STK IV L4OP MV E_CAU UK LM ACO RSLT CNT
L INDEX SPORT MAC_ADDR IP_ADDR IS1Q COS1Q SVLAN CE1Q CEQOS CEVLAN RSLT CNT
------------------------------------------------------------------------------------------------------------------------------------------
TCAM A bank 0 entries
IR V 1 6139 0 0 0 127.0.0.16 127.0.0.17 0x000 0 0 2 67 68 0x007FE00FFF7ED7DB 1type = 0
! Also see: show platform hardware cef tcam utilization detail
! Also see: show platform hardware cef tcam keys count
6506-E#show platform hardware cef tcam shadow detail
Util summary for Pool 0: 524288 keys, 1024 segs, 36 Mb
Type KeyUse SegKeyUse SegUse Util Free
0 333453 333453 682 95 337
1 20 20 3 1 337
2 4 4 2 0 336
3 0 0 0 0 252
4 0 0 0 0 336
Tot 333477 333477 687 94 337
Util summary for Pool 1: 524288 keys, 1024 segs, 36 Mb
Type KeyUse SegKeyUse SegUse Util Free
0 263148 263148 672 76 352
1 0 0 0 0 352
2 0 0 0 0 352
3 0 0 0 0 264
4 0 0 0 0 352
Tot 263148 263148 672 76 352
Util summary for Pool 4: 1048576 keys, 2048 segs, 72 Mb
Type KeyUse SegKeyUse SegUse Util Free
0 596601 596601 1354 86 689
1 20 20 3 1 689
2 4 4 2 0 688
3 0 0 0 0 516
4 0 0 0 0 688
Tot 596625 596625 1359 85 689
Key counts per Class per Pool:
Pri Pri
Class ID Pool >= <= Key-Cnt
IPv4 0 * 0 68 596599
. . 0 0 42 333451
. . 1 42 68 263148
IPv4-Mcast 1 * 0 68 9
. . 0 0 68 9
. . 1 68 68 0
MPLS 2 * 0 17 1
. . 0 0 17 1
. . 1 17 17 0
EOMPLS 3 * 0 19 1
. . 0 0 19 1
. . 1 19 19 0
MPLS-VPN 4 * 0 9 0
. . 0 0 9 0
. . 1 9 9 0
Diags 5 * 0 5 0
. . 0 0 5 0
. . 1 5 5 0
IPv6-Local 6 * 0 390 0
. . 0 0 390 0
. . 1 390 390 0
IPv6-Mcast 7 * 0 261 1
. . 0 0 261 1
. . 1 261 261 0
IPv6-Global 8 * 0 390 1
. . 0 0 390 1
. . 1 390 390 0
VPLSv4-Mcast 9 * 0 69 0
. . 0 0 69 0
. . 1 69 69 0
VPLSv6-Mcast 10 * 0 261 0
. . 0 0 261 0
. . 1 261 261 0
Key counts per Pri:
Class ID Pool Pri Key-Cnt
IPv4 0 0 34 120
. . . 35 4
. . . 36 52
. . . 37 7
. . . 38 9
. . . 39 19
. . . 40 4
. . . 41 1
. . . 42 333235
IPv4 0 1 42 7
. . . 43 58696
. . . 44 66610
. . . 45 38914
. . . 46 37051
. . . 47 24661
. . . 48 12666
. . . 49 7680
. . . 50 13081
. . . 51 1768
. . . 52 1051
. . . 53 514
. . . 54 269
. . . 55 101
. . . 56 35
. . . 57 13
. . . 58 22
. . . 62 6
. . . 67 3
IPv4-Mcast 1 0 3 6
. . . 10 3
MPLS 2 0 17 1
EOMPLS 3 0 19 1
IPv6-Mcast 7 0 115 1
IPv6-Global 8 0 390 1
Priorities in exception:
Class ID Pri (>=) Max Key-Cnt Pri-Cnt
IPv4 0 68 68 0
IPv4-Mcast 1 68 68 0
MPLS 2 17 17 0
EOMPLS 3 19 19 0
MPLS-VPN 4 9 9 0
Diags 5 5 5 0
IPv6-Local 6 390 390 0
IPv6-Mcast 7 261 261 0
IPv6-Global 8 390 390 0
VPLSv4-Mcast 9 69 69 0
VPLSv6-Mcast 10 261 261 0
In the output below it can be seen that the Cisco IOS is actively trying to optimise the ACLs and ACEs before they are programmed into the TCAM (for example since eight Value fields can be assigned to one Mask). In the first TCAM output below it can be seen the entire ACL has been squashed to just one "permit ip any any" style rule because all states are permit rules followed by a "permit ip any any" which has the same effect as if the preceding statements weren’t present. In the second set of TCAM outputs, where some explicit deny statements have been added before the "permit ip any any" statement it can been seen that only these deny statements are programmed into the TCAM, the other permit statements are not requirements because of the explicit "permit" at the end.
interface TenGigabitEthernet1/1
ip address x.x.x.x 255.255.255.252
ip access-group core-ipv4-iacl-in in
ip access-group core-ipv4-iacl-out out
end
7606#show run | sec access
ip access-list extended core-ipv4-iacl-out
permit ip 10.0.0.0 0.255.255.255 any
permit ip 172.0.0.0 0.255.255.255 any
permit ip 192.0.0.0 0.255.255.255 any
permit ip any any
7606#show tcam int ten1/1 acl out ip detail
* Global Defaults shared
-------------------------------------------------------------------------------------------------------------------
DPort - Destination Port SPort - Source Port TCP-F - U -URG Pro - Protocol
I - Inverted LOU TOS - TOS Value - A -ACK rtr - Router
MRFM - M -MPLS Packet TN - T -Tcp Control - P -PSH COD - C -Bank Care Flag
- R -Recirc. Flag - N -Non-cachable - R -RST - I -OrdIndep. Flag
- F -Fragment Flag CAP - Capture Flag - S -SYN - D -Dynamic Flag
- M -More Fragments F-P - FlowMask-Prior. - F -FIN T - V(Value)/M(Mask)/R(Result)
X - XTAG (*) - Bank Priority
-------------------------------------------------------------------------------------------------------------------
Interface: 1017 label: 1 lookup_type: 3
protocol: IP packet-type: 0
+-+-----+---------------+---------------+---------------+---------------+-------+---+----+-+---+--+---+---+
|T|Index| Dest Ip Addr | Source Ip Addr| DPort | SPort | TCP-F |Pro|MRFM|X|TOS|TN|COD|F-P|
+-+-----+---------------+---------------+---------------+---------------+-------+---+----+-+---+--+---+---+
V 17823 0.0.0.0 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- C-- 0-0
M 17828 0.0.0.0 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: PERMIT_RESULT (*) rtr_rslt: PERMIT_RESULT (*) hit_cnt=0
V 18400 0.0.0.0 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- --- 0-0
M 18404 0.0.0.0 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: L3_DENY_RESULT rtr_rslt: L3_DENY_RESULT hit_cnt=0
V 36832 0.0.0.0 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- --- 0-0
M 36836 0.0.0.0 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: L3_DENY_RESULT (*) rtr_rslt: L3_DENY_RESULT (*) hit_cnt=1
7606(config)#ip access-list extended core-ipv4-iacl-out
7606(config-ext-nacl)#5 deny ip any 1.1.1.1 0.0.0.0
7606(config-ext-nacl)#6 deny ip host 1.1.1.1 any
7606(config-ext-nacl)#^Z
7606#show tcam int ten1/1 acl out ip detail
* Global Defaults shared
-------------------------------------------------------------------------------------------------------------------
DPort - Destination Port SPort - Source Port TCP-F - U -URG Pro - Protocol
I - Inverted LOU TOS - TOS Value - A -ACK rtr - Router
MRFM - M -MPLS Packet TN - T -Tcp Control - P -PSH COD - C -Bank Care Flag
- R -Recirc. Flag - N -Non-cachable - R -RST - I -OrdIndep. Flag
- F -Fragment Flag CAP - Capture Flag - S -SYN - D -Dynamic Flag
- M -More Fragments F-P - FlowMask-Prior. - F -FIN T - V(Value)/M(Mask)/R(Result)
X - XTAG (*) - Bank Priority
-------------------------------------------------------------------------------------------------------------------
Interface: 1017 label: 1 lookup_type: 3
protocol: IP packet-type: 0
+-+-----+---------------+---------------+---------------+---------------+-------+---+----+-+---+--+---+---+
|T|Index| Dest Ip Addr | Source Ip Addr| DPort | SPort | TCP-F |Pro|MRFM|X|TOS|TN|COD|F-P|
V 17809 0.0.0.0 1.1.1.1 P=0 P=0 ------ 0 ---- 0 0 -- C-- 0-0
M 17810 0.0.0.0 255.255.255.255 0 0 ------ 0 ---- 0 0
R rslt: L3_DENY_RESULT (*) rtr_rslt: L3_DENY_RESULT (*) hit_cnt=0
V 17818 1.1.1.1 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- C-- 0-0
M 17819 255.255.255.255 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: L3_DENY_RESULT (*) rtr_rslt: L3_DENY_RESULT (*) hit_cnt=0
V 17823 0.0.0.0 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- C-- 0-0
M 17828 0.0.0.0 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: PERMIT_RESULT (*) rtr_rslt: PERMIT_RESULT (*) hit_cnt=0
V 18400 0.0.0.0 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- --- 0-0
M 18404 0.0.0.0 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: L3_DENY_RESULT rtr_rslt: L3_DENY_RESULT hit_cnt=0
V 36832 0.0.0.0 0.0.0.0 P=0 P=0 ------ 0 ---- 0 0 -- --- 0-0
M 36836 0.0.0.0 0.0.0.0 0 0 ------ 0 ---- 0 0
R rslt: L3_DENY_RESULT (*) rtr_rslt: L3_DENY_RESULT (*) hit_cnt=1
For Cisco the EARL (Encoded Address Resolution Logic) chipsets are one of their chipsets that provide the TCAM features (as well as other features like MAC learning and port relationships). In a Nexus 7K its the EARL8 chipset and in the SUP2T moduels for 6500s. In 6500/7600 using SUP720/RSP720 modules its the EARL7. The DFC modules for line cards in the 6500/7600 range include an EARL7. 7600 ES+ line cards use EARL 7.5 which is compatible with the RSP720. The Sup6-E (used in Cat4500 chassis) uses what Cisco call the "TCAM4" chipset, this is also used in ASR1000 series routers and the ME3600X and ME3800X switches. The 12000 series routers use the Wahoo TCAM module.
Task Optimised Processors (TOPs)
The following is from the book Network Processors - Architecture, Programming, and Implementation by Ran Giladi. The book is specifically about the EZChip Technologies Ltd. range of network processors however TOPs are quite general across many manufacturers including Cisco and Juniper who both use EZChip ASICs:
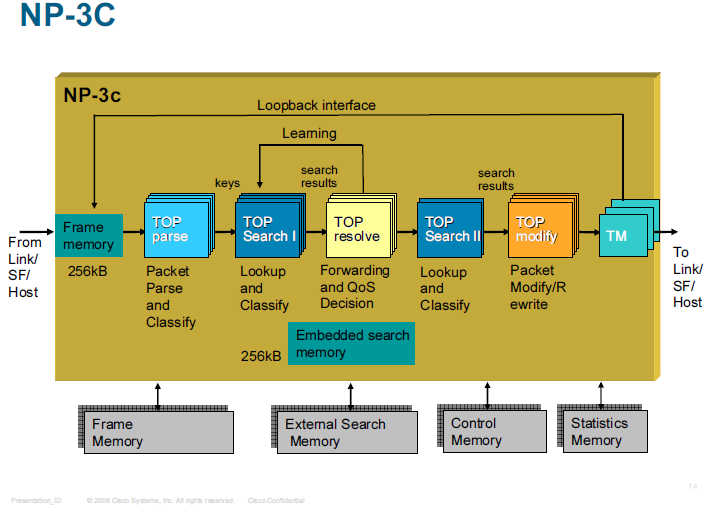
There are four types of such Task-Optimized Processors (TOP engines) employed to perform the four main tasks of packet processing, that is, parsing, searching, resolving, and modifying. Each type of TOP processor employs architecture with a customized, function specific data path, functional units, and instruction set that supports the minimum number of machine cycles required for complex seven layer packet processing.
Each TOP processor is based on a four-stage instruction pipeline that effectively results in an instruction executed every clock cycle (1 IPC). Although the TOP engines are specific for each stage, they share a common instruction set that requires only minor adjustments for operating the specific functional units and capabilities of each of the TOPs. Since there are multiple instances of the TOPs in each stage of the pipeline, the overall architecture resembles super-scalar architecture of a high degree, with the degree depending on the stage (the number of TOPs at each stage).
There are two stages in the NP pipeline that contain multiple instances of embedded search engines, also based on the TOPs architecture. These are used for lookups in a combination of tables with potentially millions of entries for implementing diverse applications in layer 2 to 4 switching and routing and layer 5 to 7 deep packet processing. Three types of lookup tables can be used by the NP: direct access tables, hash tables, and trees—each flexibly defined and used for various applications. Tables may be used for forwarding and routing, flow classification, access control, and so on. Numerous tables of each type can be defined, stored in embedded memory and/or external memory, and searched through for each packet. The key size, result size (i.e., associated data), and number of entries are all user-defined per table. Variable length entries, longest match as well as first match and random wildcards are supported.
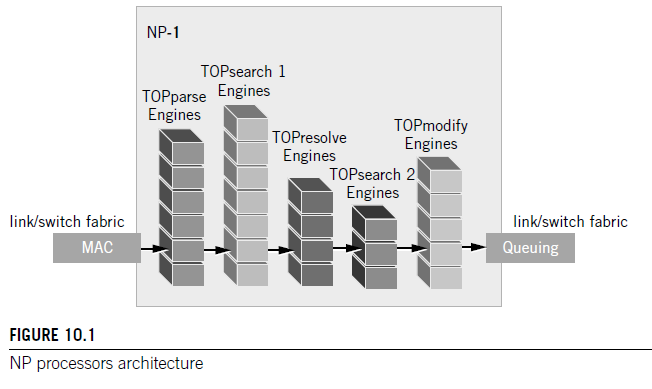
As mentioned before, there are four types of TOP engines, each tailored to perform its respective function in the various stages of packet processing, that is, parsing, lookup and classify, forwarding and decisions, and packet modifications. TOPparse identifies and extracts various packet headers, tags, addresses, ports, protocols, fields, patterns, and keywords throughout the frame. TOPparse can parse packets of any format, encapsulation method, proprietary tags, and so on. TOPsearch uses the parsed fields as keys for performing lookups in the relevant routing, classification, and policy tables. TOPresolve makes forwarding and QoS decisions, and updates tables and session state information. TOPsearchII optionally performs additional lookups after the TOPresolve decisions have been made. TOPmodify modifies packet contents, and performs overwrite, add or insert operations anywhere in the packet. The architecture of the NP is shown in Figure 10.2.
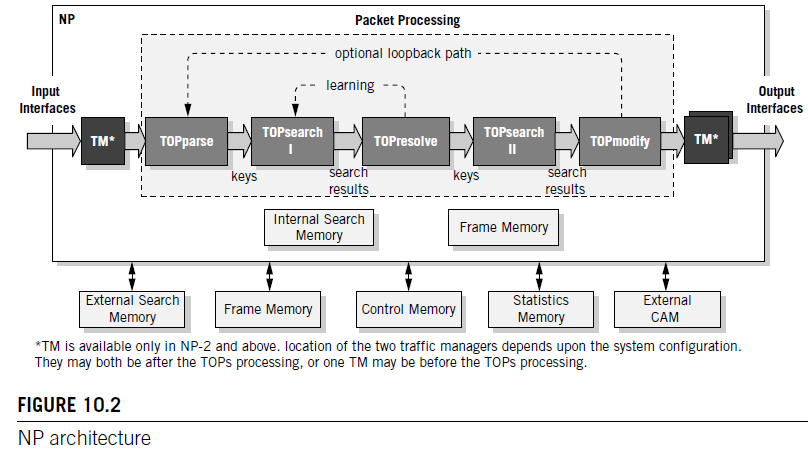
Multiple instances of each TOP type at the same pipeline stage enable simultaneous processing of multiple packets.
*End of EZChip book extract*.
Below are outputs showing utilistion stats for some parts of the Typhoon NPU on an ASR9001, there is more info on ASR9000 NP architecture and TOPs here: /index.php?page=asr9000-series-hardware-overview#np-architecture
! IOS-XE 5.3.3 on ASR9001
RP/0/RSP0/CPU0:abr1#show controllers np ports all
Node: 0/0/CPU0:
----------------------------------------------------------------
NP Bridge Fia Ports
-- ------ --- ---------------------------------------------------
0 0 0 GigabitEthernet0/0/0/0 - GigabitEthernet0/0/0/19
0 0 0 TenGigE0/0/2/0, TenGigE0/0/2/1
1 1 1 TenGigE0/0/1/0 - TenGigE0/0/1/3
1 1 1 TenGigE0/0/2/2, TenGigE0/0/2/3
RP/0/RSP0/CPU0:abr1#run
# attach 0/0/CPU0
attach: Starting session 1 to node 0/0/CPU0
# np_perf -e1 -f
Fabric interface average utilization
RX PPS RX gbps TX PPS TX gbps
----------------------------------------------------------------
ILKN 0 n/a n/a n/a n/a
ILKN 1 54541 0.2832 106665 0.7267
ILKN 2 49498 0.4054 49517 0.2011
# np_perf -e1 -l
NP engine load
parse resolve modify pps rate
-------------------------------------
0% 0% 0% 236899
NP1 search thread utilization summary
Group Free Usage
--------------------
0 23 4%
1 23 4%
2 23 4%
3 23 4%
4 23 4%
5 23 4%
6 23 4%
7 23 4%
Total Free average: 184
Total Utilization: 4%
# np_perf -e0 -s
TOPsearch engine schmoo
Groups Packets/s
---------------------
8 388581
7 376864
6 386964
5 362936
4 362799
3 388922
2 377396
1 369282
TOPsearch context schmoo
Contexts Packets/s
---------------------
24 367906
23 376623
22 419413
21 418647
20 430571
19 431915
18 381925
17 394736
16 386776
15 389609
14 407298
13 398723
12 375517
11 371825
10 343673
9 358955
8 343795
7 360151
6 373494
5 362459
4 356575
3 373847
2 348161
1 418218
TOPresolve engine schmoo
Engines Packets/s
---------------------
32 393119
31 353874
30 417807
29 365656
28 419051
27 388641
26 373994
25 394134
24 326924
23 370288
22 360729
21 369059
20 354754
19 355619
18 410171
17 371541
16 358454
15 391014
14 389342
13 355862
12 334330
11 367828
10 340210
9 342984
8 340151
7 330883
6 310596
5 341946
4 354317
3 385271
2 372225
1 369239
TOPmodify engine schmoo
Engines Packets/s
---------------------
32 333307
31 333798
30 345171
29 350981
28 338295
27 327597
26 360886
25 346606
24 334926
23 326030
22 330583
21 313526
20 348284
19 341778
18 335951
17 321818
16 343373
15 371739
14 353275
13 375070
12 355199
11 355713
10 360545
9 359599
8 351959
7 345543
6 337246
5 348807
4 354029
3 383284
2 381524
1 375551
TOPparse engine schmoo
Engines Packets/s
---------------------
32 365697
31 384796
30 351258
29 356521
28 344785
27 374156
26 335971
25 321786
24 313367
23 346504
22 321895
21 336797
20 323037
19 318640
18 327259
17 341193
16 353686
15 354764
14 396907
13 367175
12 348639
11 349437
10 357534
9 359265
8 364936
7 411514
6 383595
5 355361
4 354243
3 377395
2 383685
1 395822
# np_perf -e0 -R
RFD per-port usage and flow-control average time
FC RFD Used Guaranteed | FC RFD Used Guaranteed
Interface Pct Avg Peak Avg Peak | Interface Pct Avg Peak Avg Peak
--------------------------------------------------------+--------------------------------------------------------
NetIF 0 0 0 18 0 19 | NetIF 1 0 0 0 0 0
NetIF 2 0 2 25 2 25 | NetIF 3 0 0 0 0 0
NetIF 4 0 0 0 0 0 | NetIF 5 0 0 0 0 0
NetIF 6 0 0 0 0 0 | NetIF 7 0 0 0 0 0
TenGigE0_0_2_0 0 0 11 0 8 | TenGigE0_0_2_1 0 2 32 2 29
SGMII 0 0 0 2 0 0 | SGMII 1 0 0 0 0 0
SGMII 2 0 0 0 0 0 | SGMII 3 0 0 0 0 0
SGMII 4 0 0 12 0 0 | SGMII 5 0 0 2 0 0
GigabitEthernet0_0_0_0 0 0 0 0 0 | GigabitEthernet0_0_0_1 0 0 0 0 0
GigabitEthernet0_0_0_2 0 0 0 0 0 | GigabitEthernet0_0_0_3 0 0 0 0 0
GigabitEthernet0_0_0_8 0 0 9 0 0 | GigabitEthernet0_0_0_9 0 0 0 0 0
SGMII 12 0 0 0 0 0 | SGMII 13 0 0 0 0 0
GigabitEthernet0_0_0_10 0 0 0 0 0 | GigabitEthernet0_0_0_11 0 0 0 0 0
GigabitEthernet0_0_0_12 0 0 0 0 0 | GigabitEthernet0_0_0_13 0 0 0 0 0
GigabitEthernet0_0_0_18 0 0 0 0 0 | GigabitEthernet0_0_0_19 0 0 0 0 0
SGMII 20 0 0 0 0 0 | SGMII 21 0 0 0 0 0
SGMII 22 0 0 0 0 0 | SGMII 23 0 0 0 0 0
SGMII 24 0 0 0 0 0 | SGMII 25 0 0 0 0 0
SGMII 26 0 0 0 0 0 | SGMII 27 0 0 0 0 0
SGMII 28 0 0 0 0 0 | SGMII 29 0 0 0 0 0
GigabitEthernet0_0_0_4 0 0 0 0 0 | GigabitEthernet0_0_0_5 0 0 0 0 0
GigabitEthernet0_0_0_6 0 0 0 0 0 | GigabitEthernet0_0_0_7 0 0 0 0 0
SGMII 34 0 0 0 0 0 | SGMII 35 0 0 0 0 0
SGMII 36 0 0 0 0 0 | SGMII 37 0 0 0 0 0
GigabitEthernet0_0_0_14 0 0 0 0 0 | GigabitEthernet0_0_0_15 0 0 0 0 0
GigabitEthernet0_0_0_16 0 0 0 0 0 | GigabitEthernet0_0_0_17 0 0 0 0 0
SGMII 42 0 0 0 0 0 | SGMII 43 0 0 0 0 0
SGMII 44 0 0 0 0 0 | SGMII 45 0 0 0 0 0
SGMII 46 0 0 0 0 0 | SGMII 47 0 0 0 0 0
HSGMII 0 0 0 0 0 0 | HSGMII 1 0 0 0 0 0
Host HP 0 0 0 0 0 | Host LP 0 0 0 0 0
CPU 0 HP 0 0 0 0 0 | CPU 0 LP 0 0 0 0 0
CPU 1 HP 0 0 0 0 0 | CPU 1 LP 0 0 0 0 0
Lpbk 0 0 0 0 0 0 | Lpbk 1 0 0 0 0 0
Internal Frame Memory Bank Utilization
Bank Avg RFD Usage Peak RFD Usage
--------------------------------------------
RFD Bank 0 72 86
RFD Bank 1 65 82
RFD Bank 2 78 88
RFD Bank 3 74 90
ICFD/OCFD Queue fullness and peak level
Queue Avg Level Peak Level
--------------------------------------------
ICFDQ 0 2
OCFDQ 0 2
The following diagram which shows what happens when a TOP inside an Cisco ASR9000 NPU experiances a lock-up, shows the TOPs design and their tasks:
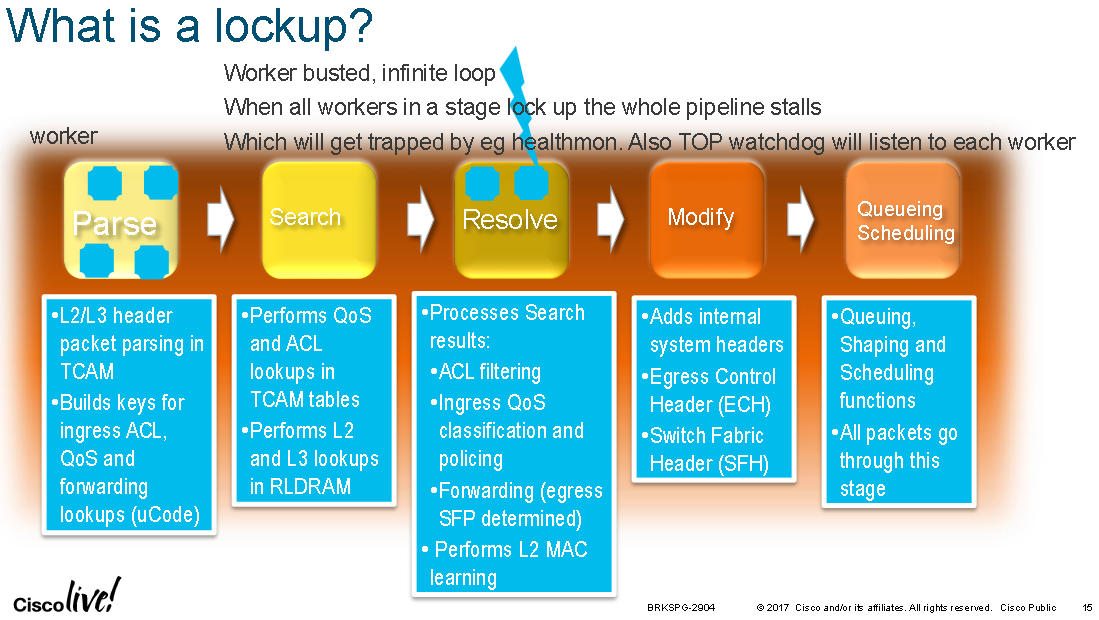
The following slides show the TOPs for the 7600 ES+ line cards:

Previous page: Encoding Schemes
Next page: PHY, MII and MAC